Pattern recognition systems examples. General characteristics of pattern recognition problems and their types. Pattern recognition methods
In general, three methods of pattern recognition can be distinguished: Brute force method. In this case, a comparison is made with a database, where for each type of object various display modifications are presented. For example, for optical pattern recognition, you can use the method of enumerating the appearance of an object at various angles, scales, displacements, deformations, etc. For letters, you need to enumerate the font, font properties, etc. In the case of sound image recognition, accordingly, a comparison is made with some known patterns (for example, a word spoken by several people).
The second approach involves a more in-depth analysis of the characteristics of the image. In the case of optical recognition, this may be the determination of various geometric characteristics. In this case, the sound sample is subjected to frequency, amplitude analysis, etc.
The next method is the use of artificial neural networks (ANN). This method requires either a large number of examples of the recognition task during training, or a special neural network structure that takes into account the specifics of this task. However, it offers higher efficiency and productivity.
4. History of pattern recognition
Let us briefly consider the mathematical formalism of pattern recognition. An object in pattern recognition is described by a set of basic characteristics (features, properties). The main characteristics can be of a different nature: they can be taken from an ordered set of the real line type, or from a discrete set (which, however, can also be endowed with structure). This understanding of an object is consistent both with the need for practical applications of pattern recognition and with our understanding of the mechanism of human perception of an object. Indeed, we believe that when a person observes (measures) an object, information about it arrives through a finite number of sensors (analyzed channels) to the brain, and each sensor can be associated with a corresponding characteristic of the object. In addition to the features that correspond to our measurements of the object, there is also a selected feature, or a group of features, which we call classifying features, and finding out their values for a given vector X is the task performed by natural and artificial recognition systems.
It is clear that in order to establish the values of these features, it is necessary to have information about how the known features are related to the classifying ones. Information about this connection is given in the form of precedents, that is, a set of descriptions of objects with known values of classifying characteristics. And based on this precedent information, it is necessary to construct a decision rule that will assign to an arbitrary description of an object the values of its classifying features.
This understanding of the problem of pattern recognition has been established in science since the 50s of the last century. And then it was noticed that such a production was not new at all. We have encountered a similar formulation and there already existed quite well-proven methods of statistical data analysis, which were actively used for many practical problems, such as, for example, technical diagnostics. Therefore, the first steps of pattern recognition took place under the sign of a statistical approach, which dictated the main problems.
The statistical approach is based on the idea that the original space of objects is a probabilistic space, and the signs (characteristics) of objects are random variables specified on it. Then the task of the data scientist was to, based on certain considerations, put forward a statistical hypothesis about the distribution of features, or more precisely, about the dependence of the classifying features on the others. The statistical hypothesis, as a rule, was a parametrically defined set of feature distribution functions. A typical and classical statistical hypothesis is the hypothesis about the normality of this distribution (statisticians have come up with a great many varieties of such hypotheses). After formulating the hypothesis, it remained to test this hypothesis on precedent data. This test consisted of selecting a certain distribution from an initially specified set of distributions (parameter of the distribution hypothesis) and assessing the reliability (confidence interval) of this choice. Actually, this distribution function was the answer to the problem, only the object was no longer classified unambiguously, but with certain probabilities of belonging to classes. Statisticians have also developed an asymptotic justification for such methods. Such justifications were made according to the following scheme: a certain functional for the quality of distribution choice was established (confidence interval) and it was shown that with an increase in the number of precedents, our choice with a probability tending to 1 became correct in the sense of this functional (confidence interval tending to 0). Looking ahead, we will say that the statistical view of the problem of recognition turned out to be very fruitful not only in terms of the developed algorithms (which include methods of cluster and discriminant analysis, nonparametric regression, etc.), but also subsequently led Vapnik to the creation of a deep statistical theory of recognition .
However, there is a strong argument to be made that pattern recognition problems are not reducible to statistics. Any such problem, in principle, can be considered from a statistical point of view and the results of its solution can be interpreted statistically. To do this, it is only necessary to assume that the object space of the problem is probabilistic. But from the point of view of instrumentalism, the criterion for the success of a statistical interpretation of a certain recognition method can only be the presence of justification for this method in the language of statistics as a branch of mathematics. Justification here means the development of basic requirements for the task that ensure success in applying this method. However, on this moment For most recognition methods, including those that directly arose within the framework of the statistical approach, such satisfactory justifications have not been found. In addition, the most commonly used statistical algorithms at the moment, such as the Fisher linear discriminant, the Parzen window, the EM algorithm, the nearest neighbor method, not to mention Bayesian belief networks, have a strongly heuristic nature and may have interpretations that differ from statistical ones. And finally, to all of the above, it should be added that in addition to the asymptotic behavior of recognition methods, which is the main issue of statistics, the practice of recognition raises questions of the computational and structural complexity of methods that go far beyond the scope of probability theory alone.
So, contrary to the aspirations of statisticians to consider pattern recognition as a branch of statistics, completely different ideas were included in the practice and ideology of recognition. One of them was caused by research in the field of visual pattern recognition and is based on the following analogy.
As already noted, in everyday life people constantly solve (often unconsciously) problems of recognizing various situations, auditory and visual images. Such a capability for computers is, at best, a thing of the future. Hence, some pioneers of pattern recognition concluded that the solution to these problems on a computer should be general outline simulate the processes of human thinking. The most famous attempt to approach the problem from this angle was F. Rosenblatt's famous study on perceptrons.
By the mid-50s, it seemed that neurophysiologists had understood the physical principles of the brain (in the book “The New Mind of the King,” the famous British theoretical physicist R. Penrose interestingly questions the neural network model of the brain, justifying the significant role of quantum mechanical effects in its functioning ; although, however, this model was questioned from the very beginning. Based on these discoveries, F. Rosenblatt developed a model for learning visual image recognition, which he called the Rosenblatt perceptron, which represents the following function (Fig. 1):
Fig 1. Perceptron circuit
At the input, the perceptron receives an object vector, which in Rosenblatt’s work was a binary vector showing which of the screen pixels is blackened by the image and which is not. Next, each of the signs is fed to the input of a neuron, the action of which is a simple multiplication by a certain weight of the neuron. The results are fed to the last neuron, which adds them up and compares the total amount with a certain threshold. Depending on the comparison results, the input object X is recognized as required or not. Then the task of teaching pattern recognition was to select neuron weights and threshold values so that the perceptron would give correct answers on precedent visual images. Rosenblatt believed that the resulting function would be good at recognizing the desired visual image even if the input object was not among the precedents. For bionic reasons, he also came up with a method for selecting weights and thresholds, which we will not dwell on. Let’s just say that his approach turned out to be successful in a number of recognition problems and gave rise to a whole direction of research into learning algorithms based on neural networks, a special case of which is the perceptron.
Further, various generalizations of the perceptron were invented, the function of neurons was complicated: neurons could now not only multiply input numbers or add them and compare the result with thresholds, but apply more complex functions. Figure 2 shows one of these neuron complications:

Rice. 2 Diagram of a neural network.
In addition, the topology of the neural network could be much more complex than the one considered by Rosenblatt, for example this:
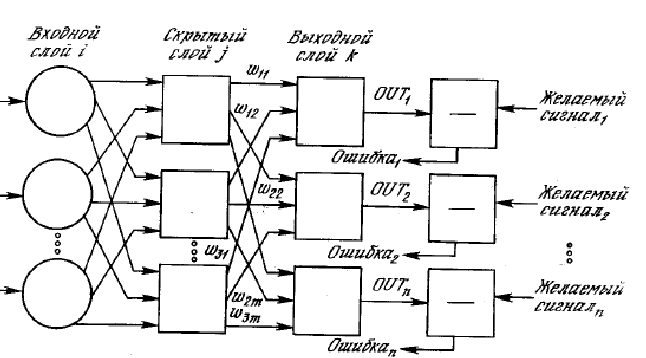
Rice. 3. Rosenblatt neural network diagram.
Complications led to an increase in the number of adjustable parameters during training, but at the same time increased the ability to tune into very complex patterns. Research in this area is now proceeding in two closely related directions - various network topologies and various configuration methods are being studied.
Neural networks are currently not only a tool for solving pattern recognition problems, but have also been used in research on associative memory and image compression. Although this area of research intersects strongly with the problems of pattern recognition, it represents a separate branch of cybernetics. For a recognizer at the moment, neural networks are nothing more than a very specifically defined, parametrically defined set of mappings, which in this sense does not have any significant advantages over many other similar learning models that will be briefly listed below.
In connection with this assessment of the role of neural networks for recognition itself (that is, not for bionics, for which they are of paramount importance now), I would like to note the following: neural networks, being an extremely complex object for mathematical analysis, when used correctly, make it possible to find very non-trivial laws in the data. Their difficulty for analysis, in general, is explained by their complex structure and, as a consequence, practically inexhaustible possibilities for generalizing a wide variety of patterns. But these advantages, as often happens, are a source of potential errors and the possibility of retraining. As will be discussed below, such a dual view of the prospects of any learning model is one of the principles of machine learning.
Another popular direction in recognition is logical rules and decision trees. In comparison with the above-mentioned recognition methods, these methods most actively use the idea of expressing our knowledge about the subject area in the form of probably the most natural (at a conscious level) structures - logical rules. An elementary logical rule means a statement like “if unclassifiable features are in relation X, then classified ones are in relation Y.” An example of such a rule in medical diagnostics is the following: if the patient is over 60 years old and has previously suffered a heart attack, then do not perform the operation - the risk of a negative outcome is high.
To search for logical rules in data, two things are needed: to determine the measure of “informativeness” of the rule and the space of rules. And the task of searching for rules then turns into a task of full or partial enumeration in the space of rules in order to find the most informative of them. The definition of information content can be introduced by the most different ways and we will not dwell on this, considering that this is also some parameter of the model. The search space is defined in a standard way.
After finding sufficiently informative rules, the phase of “assembling” the rules into the final classifier begins. Without discussing in depth the problems that arise here (and there are a considerable number of them), we will list 2 main methods of “assembly”. The first type is a linear list. The second type is weighted voting, when each rule is assigned a certain weight, and the object is assigned by the classifier to the class for which the largest number of rules voted.
In effect, the rule-building phase and the "assembly" phase run together and, when constructing a weighted vote or list, rule lookup on parts of the case data is called again and again to ensure a better fit between the data and the model.
Annotation: We want to come to an understanding of the phenomenon of thinking, starting from the tasks of behavior and perception, that is, from the tasks for which the brain arose and evolved. In previous lectures we talked about behavior. Now let's see what the perception task provides for understanding the phenomenon of thinking. We will look at some principles of “intelligent” perception, which are illustrated by the example of solving the problem of automatically reading handwritten characters. Practical orientation did not lead, as often happens, to simplification and emasculation of the problem of perception. On the contrary, to obtain a workable solution, it was necessary to introduce “intelligent” components focused on recognition “with understanding.”
Pattern recognition
From the very beginning of the development of cybernetics, machine perception of images was most often chosen for the study and modeling of intelligence and, in particular, such obvious components of thinking as building a system of generalized knowledge about the environment and using this knowledge in the process decision making. The perception of visual information seemed to be the most convenient for modeling and at the same time the most practically significant.
It was immediately clear that to fully solve the problem of machine visual perception, “intelligent” recognition, or recognition “with understanding,” is necessary. Often they even tried to reduce thinking to perception, simply putting a sign of identity between them. We will see later that thinking and perception are inextricably linked, but they are far from the same thing. Therefore, studies of living perception (primarily visual) are certainly useful for understanding the thinking process, but the problem as a whole is far from solving the problem. At the same time, the practical orientation of work in the field of automatic analysis of visual information and the desire for technical feasibility have led to a serious transformation of the problem. It turned out to be almost almost forced to simplify the consideration of the process of perception by reducing it to classification according to the characteristics of simple objects considered separately. This direction became known as " Pattern recognition".
Pattern recognition to the direction " Artificial intelligence"(AI) was most often not included, since, unlike AI problems, a well-developed mathematical apparatus appeared in image recognition, and for not very complex objects, it turned out to be possible to build practically working recognition (classification) systems. As a result, the traditional pattern recognition, on the one hand, does not solve the problem of machine analysis of complex images and, on the other hand, is not a serious tool for modeling intelligence. Let us consider the issues related to this in more detail.
For any recognition, standards or models of classes of recognized objects are needed. Classification of recognition methods is possible according to the types of standards used or, which is almost the same, according to the method of representing objects at the input of the recognition system. Most image recognition systems typically use raster, feature, or structure methods.
The raster approach corresponds to standards that are images or some kind of image preparations. During recognition, the input image presented in the form of a dot raster is compared point to point with all the reference ones and it is determined which of the standards the image matches better, for example, has more common points. The input and reference images must be the same size and orientation. For example, in the so-called multifont-OCR (multifont printed text recognizers), this is achieved by constructing different standards not only for different fonts, but also for different character sizes (points) within the same font. Recognition of handwritten characters in this way is impossible due to their too great variability in shape, size and orientation.
It is also possible use case raster recognition with reduction of the input image to standard sizes and orientation. In this case, recognition of handwritten characters using the raster method becomes possible after clustering each recognized class and creating a separate raster standard for each cluster.
In general, obtaining invariance with respect to the size, shape and orientation of objects recognized by raster is a complex and often insoluble problem. Another problem arises from the need to isolate a fragment from an image that relates to a separate object. This problem is common to all classical pattern recognition methods.
In the vast majority of recognition systems and, in particular, in existing omnifont optical reading systems, the main method is the feature method. In the feature-based approach, standards are constructed using features identified in the image. The image at the input of the recognition system is represented by a feature vector. Anything can be considered as signs - any characteristics of recognizable objects. Features must be invariant to the orientation, size, and shape variations of objects. It is also desirable that feature vectors belonging to different objects of the same class belong to a convex compact region of the feature space. Feature space must be fixed and identical for all recognized objects. The alphabet of features is invented by the system developer. The quality of recognition largely depends on how well the alphabet of features is invented. There is no general method for automatically constructing an optimal alphabet of features.
Recognition consists of a priori obtaining a complete vector of features for any individual recognizable object selected in the image and only then determining which of the standards this vector corresponds to. Standards are most often constructed as statistical or geometric objects. In the first case, training may consist, for example, of obtaining a matrix of frequencies of occurrence of each feature in each class of objects, and recognition may consist of determining the probabilities of the feature vector belonging to each of the standards.
In the geometric approach, the result of training is most often the division of the feature space into areas corresponding to different classes of recognized objects, and recognition consists of determining which of these areas the input feature vector corresponding to the recognized object falls into. Difficulties in assigning an input feature vector to any area may arise if areas intersect, and also if the areas corresponding to individual recognized classes are not convex and are located in the feature space in such a way that the recognized class is not separated from other classes by a single hyperplane. These problems are most often solved heuristically, for example, by calculating and comparing distances (not necessarily Euclidean) in the feature space from the examined object to the centers of gravity of subsets of the training sample corresponding to different classes. More radical measures are also possible, for example, changing the alphabet of features or clustering the training set, or both at the same time.
The structural approach corresponds to standard descriptions constructed in terms of the structural parts of objects and spatial relations between them. Structural elements are highlighted, as a rule, on the contour or “skeleton” of the object. Most often, a structural description can be represented by a graph that includes structural elements and the relationships between them. During recognition, a structural description of the input object is constructed. This description is compared with all structural standards, for example, graph isomorphism is found.
Raster and structural methods are sometimes reduced to a feature approach, considering in the first case image points as features, and in the second - structural elements and relationships between them. Let us immediately note that there is a very important fundamental difference between these methods. The raster method has the property of integrity. Structural method may have the property of integrity. The attribute method does not have the property of integrity.
What is integrity, and what role does it play in perception?
Classic pattern recognition usually organized as a sequential process unfolding “from the bottom up” (from image to understanding) in the absence of perception control from the upper conceptual levels. The recognition stage is preceded by the stage of obtaining an a priori description of the input image. Operations of selecting elements of this description, for example, features, or structural elements, are performed locally on the image, parts of the image receive an independent interpretation, that is, there is no holistic perception, which in general can lead to errors - a fragment of the image considered in isolation can often be interpreted completely differently depending on the hypothesis of perception, i.e. , what kind of holistic object is supposed to be seen.
Secondly, traditional approaches are focused on recognizing (classifying) objects considered individually. The stage of recognition itself must be preceded by the stage of segmentation (splitting) the image into parts corresponding to the images of individual objects being recognized. A priori segmentation methods typically exploit specific properties of the input image. General solution There is no pre-segmentation task. Except in the simplest cases, the separation criterion cannot be formulated in terms of local properties of the image itself, i.e., before it is recognized.
Lowercase, even handwritten, text is not the most difficult case, but even for such images, highlighting lines, words and individual characters in words can be a serious problem. The practical solution to this problem often relies on tinkering with segmentation options, which is completely different from what the human or animal brain does during holistic, goal-directed visual perception. Let us remember what Sechenov said: “We do not hear and see, but listen and look.” Such active perception requires holistic representations of objects at all levels - from individual parts to complete scenes - and the interpretation of parts only as part of the whole.
Thus, the disadvantages of most traditional approaches and, first of all, the attribute approach are the lack of integrity of perception, lack of focus and consistent unidirectional organization of the process “bottom up”, or from image to “understanding”.
Recognition is also possible using artificial or formal recognition neural networks (RNNs), shrouded in almost mystical fog. Sometimes they are even considered as some kind of analogue of the brain. Recently, texts simply write “neural networks,” omitting the adjectives “artificial” or “formal.” In fact, an RNN is most often just a feature classifier that builds separating hyperplanes in feature space.
The formal neuron used in these networks is an adder with a threshold element that calculates the sum of the products of feature values by some coefficients, which are nothing more than the coefficients of the equation of the separating hyperplane in feature space. If the sum is less than the threshold, then the feature vector is on one side of the dividing plane, if it is more, on the other. That's all. Apart from constructing separating hyperplanes and classification based on characteristics, there are no miracles.
The introduction in a formal neuron, instead of a threshold jump from - 1 to 1, of a smooth (differentiable), most often sigma-shaped transition, does not fundamentally change anything, but only allows the use of gradient algorithms for training the network, that is, finding the coefficients in the equations of the dividing planes, and “smearing” the dividing plane boundaries, assigning the recognition result, that is, the work of a formal neuron near the boundary, a score, for example, in the range from 0 to 1. This score, to a certain extent, can reflect the “confidence” of the system in assigning the input vector to one or another of the shared regions of the feature space. At the same time, this estimate, strictly speaking, is neither a probability nor a distance to the separating plane.
A network of formal neurons can also approximate nonlinear dividing surfaces with planes and combine unconnected regions of the feature space based on the result. This is what is done in multilayer networks.
In all cases, a feature recognition formal neural network (PRNN) is a feature classifier that builds separating hyperplanes and selects areas in a fixed space of features (characteristics). The PRNS cannot solve any other problems, and the PRNS solves the recognition problem no better than conventional feature recognizers using analytical methods.
In addition, in addition to feature recognizers, raster, including ensemble, recognizers can be built on formal neurons. In this case, all the noted disadvantages of raster recognizers are preserved. True, there may be some advantages, which we will talk about later.
To avoid misunderstandings, it should be noted that it is, in principle, possible to build a universal computer on formal neurons, using both dividing planes in the space of variables and the logical functions AND, OR and NOT, easily implemented on formal neurons, but no one is building such computers and discussion of related with this issue goes beyond the scope of the problems under consideration. Neurocomputers are usually called either simply a neural recognizer, or special systems problem solving, which are close to pattern recognition and actually use recognition based on the construction of separating hyperplanes in the feature space or based on comparison of a raster with a standard.
It was already noted above that for modeling thinking it is very important, and perhaps necessary, to understand how the neural mechanisms of the living brain work. In this regard, the question arises: aren’t formal recognition neural networks, if not a solution to the problem of modeling the neural mechanisms of the brain, then at least an important step in this direction? Unfortunately, the answer must be no. Unlike an active living neural network, RIS is a passive feature or raster classifier with all the disadvantages of traditional classifiers. We will consider the arguments on the basis of which this conclusion was made in more detail later.
So, traditional, primarily feature-based, recognition systems, based on the sequential organization of the process of recognition and classification of objects considered separately, cannot effectively solve the problem of perceiving complex visual information, mainly due to the lack of integrity and purposefulness of perception, lack of integrity in descriptions (standards) of recognized objects and sequential organization of the recognition process. For the same reason, such pattern recognition systems provide little insight into live visual perception and the thinking process.
Living systems, including humans, have been constantly confronted with the problem of pattern recognition since their appearance. In particular, information coming from the senses is processed by the brain, which in turn sorts the information, ensures decision-making, and then, using electrochemical impulses, transmits the necessary signal further, for example, to the movement organs, which implement the necessary actions. Then the environment changes, and the above phenomena occur again. And if you look at it, each stage is accompanied by recognition.
With the development of computer technology, it has become possible to solve a number of problems that arise in the process of life, to facilitate, speed up, and improve the quality of the result. For example, the operation of various life support systems, human-computer interaction, the emergence of robotic systems, etc. However, we note that it is currently not possible to provide a satisfactory result in some tasks (recognition of fast-moving similar objects, handwritten text).
Purpose of the work: to study the history of image recognition systems.
Indicate the qualitative changes that have occurred in the field of pattern recognition, both theoretical and technical, indicating the reasons;
Discuss methods and principles used in computing;
Give examples of prospects that are expected in the near future.
1. What is pattern recognition?
First studies with computer technology basically followed the classical scheme of mathematical modeling - mathematical model, algorithm and calculation. These were the tasks of modeling the processes occurring during explosions atomic bombs, calculation of ballistic trajectories, economic and other applications. However, in addition to the classical ideas of this series, methods based on a completely different nature arose, and as the practice of solving some problems showed, they often gave better results than solutions based on overcomplicated mathematical models. Their idea was to abandon the desire to create an exhaustive mathematical model of the object being studied (moreover, it was often almost impossible to construct adequate models), and instead to be satisfied with the answer only to specific questions that interest us, and to seek these answers from considerations common to a wide class of problems. Research of this kind included recognition of visual images, forecasting crop yields, river levels, the task of distinguishing oil-bearing and aquifers based on indirect geophysical data, etc. A specific answer in these tasks was required in a fairly simple form, such as, for example, whether an object belongs to one of the pre-fixed classes. And the initial data of these tasks, as a rule, were given in the form of fragmentary information about the objects being studied, for example, in the form of a set of pre-classified objects. From a mathematical point of view, this means that pattern recognition (and this is how this class of problems was called in our country) is a far-reaching generalization of the idea of function extrapolation.
The importance of such a statement for technical sciences there is no doubt and this in itself justifies numerous studies in this area. However, the problem of pattern recognition also has a broader aspect for natural science (however, it would be strange if something so important for artificial cybernetic systems did not have significance for natural ones). The context of this science also organically included questions posed by ancient philosophers about the nature of our knowledge, our ability to recognize images, patterns, and situations in the surrounding world. In fact, there is little doubt that the mechanisms for recognizing the simplest images, such as images of an approaching dangerous predator or food, were formed much earlier than the emergence of elementary language and formal logical apparatus. And there is no doubt that such mechanisms are quite developed in higher animals, which also in their life activities urgently need the ability to distinguish a rather complex system of signs of nature. Thus, in nature we see that the phenomenon of thinking and consciousness is clearly based on the ability to recognize images, and the further progress of the science of intelligence is directly related to the depth of understanding of the fundamental laws of recognition. Understanding the fact that the above issues go far beyond the standard definition of pattern recognition (in the English-language literature the term supervised learning is more common), it is also necessary to understand that they have deep connections with this relatively narrow (but still far from exhausted) direction.
Already now, pattern recognition has become firmly established in daily life and is one of the most vital knowledge of the modern engineer. In medicine, pattern recognition helps doctors make more accurate diagnoses; in factories, it is used to predict defects in batches of goods. Biometric personal identification systems as their algorithmic core are also based on the results of this discipline. Further development artificial intelligence, in particular the design of fifth-generation computers capable of more direct communication with humans in languages natural to humans and through speech, is unthinkable without recognition. Robotics is just a stone's throw away here, artificial systems controls containing recognition systems as vital subsystems.
That is why the development of pattern recognition from the very beginning attracted a lot of attention from specialists of various profiles - cybernetics, neurophysiologists, psychologists, mathematicians, economists, etc. It is largely for this reason that modern pattern recognition itself is fueled by the ideas of these disciplines. Without claiming completeness (and it is impossible to claim it in a short essay), we will describe the history of pattern recognition and key ideas.
Definitions
Before proceeding to the main methods of pattern recognition, we present a few necessary definitions.
Pattern recognition (objects, signals, situations, phenomena or processes) is the task of identifying an object or determining any of its properties from its image (optical recognition) or audio recording (acoustic recognition) and other characteristics.
One of the basic ones is the concept of set, which does not have a specific formulation. In a computer, a set is represented as a set of non-repeating elements of the same type. The word "non-repeating" means that some element in the set is either there or it is not there. A universal set includes all elements possible for the problem being solved; an empty set does not contain any.
An image is a classification grouping in a classification system that unites (highlights) a certain group of objects according to a certain criterion. Images have a characteristic property, which manifests itself in the fact that familiarization with a finite number of phenomena from the same set makes it possible to recognize as much as you like. big number its representatives. Images have characteristic objective properties in the sense that different people, trained on different observational material, for the most part classify the same objects in the same way and independently of each other. In the classical formulation of the recognition problem, the universal set is divided into image parts. Each mapping of an object onto the perceptive organs of the recognition system, regardless of its position relative to these organs, is usually called an image of the object, and sets of such images, united by some general properties, represent images.
The method of assigning an element to any image is called decisive rule. Another important concept is metric, a way of determining the distance between elements of a universal set. The smaller this distance, the more similar the objects (symbols, sounds, etc.) are - what we recognize. Typically, elements are specified as a set of numbers, and the metric is specified as a function. The efficiency of the program depends on the choice of image representation and the implementation of the metric; one recognition algorithm with different metrics will make mistakes with different frequencies.
Learning is usually called the process of developing in a certain system one or another reaction to groups of external identical signals through repeated exposure to the system of external adjustments. Such external adjustments in training are usually called “rewards” and “punishments”. The mechanism for generating this adjustment almost completely determines the learning algorithm. Self-learning differs from training in that here additional information about the correctness of the reaction to the system is not provided.
Adaptation is the process of changing the parameters and structure of the system, and possibly control actions, based on current information in order to achieve a certain state of the system under initial uncertainty and changing operating conditions.
Learning is a process as a result of which the system gradually acquires the ability to respond with the necessary reactions to certain sets of external influences, and adaptation is the adjustment of the parameters and structure of the system in order to achieve the required quality of control in conditions of continuous changes external conditions.
Examples of pattern recognition tasks: - Letter recognition;
Image, class - a classification grouping in a classification system that unites (highlights) a certain group of objects according to some criterion.The imaginative perception of the world is one of the mysterious properties of the living brain, which allows one to understand the endless flow of perceived information and maintain orientation in the ocean of disparate data about the outside world. When perceiving the external world, we always classify the perceived sensations, that is, we divide them into groups of similar, but not identical phenomena. For example, despite the significant difference, one group includes all the letters A, written in different handwritings, or all sounds that correspond to the same note, taken in any octave and on any instrument, and the operator controlling a technical object for the whole many states object reacts with the same reaction. It is characteristic that to formulate a concept about a group of perceptions of a certain class, it is enough to become familiar with a small number of its representatives. A child can be shown a letter just once so that he can find this letter in a text written in different fonts, or recognize it, even if it is written in a deliberately distorted form. This property of the brain allows us to formulate such a concept as an image.
Images have a characteristic property, which manifests itself in the fact that familiarization with a finite number of phenomena from the same set makes it possible to recognize an arbitrarily large number of its representatives. Examples of images can be: river, sea, liquid, music by Tchaikovsky, poetry by Mayakovsky, etc. A certain set of states of a control object can also be considered as an image, and this entire set of states is characterized by the fact that in order to achieve a given goal, the same impact on an object . Images have characteristic objective properties in the sense that different people, trained on different observational material, for the most part classify the same objects in the same way and independently of each other. It is this objectivity of images that allows people all over the world to understand each other.
The ability to perceive the external world in the form of images allows one to recognize with a certain reliability an infinite number of objects based on familiarization with a finite number of them, and the objective nature of the main property of images allows one to model the process of their recognition. Being a reflection of objective reality, the concept of an image is as objective as reality itself, and therefore can itself be an object of special study.
In the literature devoted to the problem of learning pattern recognition (PR), the concept of a class is often introduced instead of the concept of an image.
The problem of learning pattern recognition (PRT)
One of the most interesting properties of the human brain is its ability to respond to infinite set states of the external environment with a finite number of reactions. Perhaps it was precisely this property that allowed man to achieve the highest form of existence of living matter, expressed in the ability to think, i.e., actively reflect the objective world in the form of images, concepts, judgments, etc. Therefore, the problem of ORR arose in the study of the physiological properties of the brain .
Let's consider an example of problems from the field of ODO.
Rice. 3.1.
There are 12 images presented here, and you should select features that can help you distinguish the left triad of pictures from the right. Solving these problems requires modeling logical thinking in full.
In general, the problem of pattern recognition consists of two parts: training and recognition. Training is carried out by showing individual objects indicating their belonging to one or another image. As a result of training, the recognition system must acquire the ability to respond with the same reactions to all objects of the same image and with different reactions to all objects of different images. It is very important that the learning process should be completed only by showing a finite number of objects without any other prompts. The learning objects can be either pictures or other visual images (letters), or various phenomena of the external world, for example, sounds, body conditions during a medical diagnosis, the state of a technical object in control systems, etc. It is important that only the objects themselves and their belonging to the image. Training is followed by the process of recognizing new objects, which characterizes the actions of an already trained system. Automation of these procedures is the problem of teaching pattern recognition. In the case when a person solves or invents it himself, and then imposes a classification rule on the machine, the recognition problem is partially solved, since the person takes on the main and main part of the problem (training).
The problem of teaching pattern recognition is interesting from both an applied and a fundamental point of view. From an applied point of view, solving this problem is important primarily because it opens up the possibility of automating many processes that until now have been associated only with the activity of the living brain. The fundamental significance of the problem is closely related to the question that increasingly arises in connection with the development of ideas in cybernetics: what can and what can a machine fundamentally not do? To what extent can the capabilities of a machine be close to those of a living brain? In particular, can a machine develop the ability to take over from a person the ability to perform certain actions depending on the situations that arise in the world? environment? So far, it has only become clear that if a person can first realize his skill himself, and then describe it, that is, indicate why he performs actions in response to each state of the external environment or how (by what rule) he combines individual objects into images, then such a skill can be transferred to a machine without fundamental difficulties. If a person has a skill, but cannot explain it, then there is only one way to transfer the skill to a machine - teaching by examples.
The range of problems that can be solved using recognition systems is extremely wide. This includes not only the tasks of recognizing visual and auditory images, but also the tasks of recognizing complex processes and phenomena that arise, for example, when choosing appropriate actions by the head of an enterprise or choosing the optimal management of technological, economic, transport or military operations. In each of these tasks, certain phenomena, processes, and states of the external world are analyzed, which are referred to below as objects of observation. Before you begin to analyze any object, you need to obtain certain, ordered information about it in some way. Such information represents the characteristics of objects, their display on a variety of perceptive organs of the recognition system.
But each object of observation can affect us differently, depending on the conditions of perception. For example, any letter, even written in the same way, can, in principle, be displaced in any way relative to the perceiving organs. In addition, objects of the same image can be quite different from each other and, naturally, have different effects on the perceiving organs.
Each mapping of an object onto the perceptive organs of the recognition system, regardless of its position relative to these organs, is usually called an image of the object, and sets of such images, united by some common properties, are images.
When solving control problems using pattern recognition methods, the term “state” is used instead of the term “image”. State- this is a certain form of display of the measured current (or instantaneous) characteristics of the observed object. The set of states determines the situation. The concept of "situation" is analogous to the concept of "image". But this analogy is not complete, since not every image can be called a situation, although every situation can be called an image.
A situation is usually called a certain set of states of a complex object, each of which is characterized by the same or similar characteristics of the object. For example, if a certain control object is considered as an object of observation, then the situation combines such states of this object in which the same control actions should be applied. If the object of observation is a war game, then the situation combines all game states that require, for example, a powerful tank strike with air support.
The choice of the initial description of objects is one of the central tasks of the ODO problem. If the initial description (feature space) is successfully chosen, the recognition task may turn out to be trivial, and conversely, an unsuccessfully chosen initial description can lead to either very complex further processing of information or no solution at all. For example, if the problem of recognizing objects that differ in color is being solved, and signals received from weight sensors are chosen as the initial description, then the recognition problem cannot, in principle, be solved.
An image is understood as a structured description of the object or phenomenon being studied, represented by a vector of features, each element of which represents the numerical value of one of the features characterizing the corresponding object.
The general structure of the recognition system is as follows:
The meaning of the recognition task is to establish whether the objects under study have a fixed finite set of features that allow them to be classified into a certain class. Recognition tasks have the following characteristic features:
1. These are information tasks consisting of two stages:
a. Reducing the source data to a form convenient for recognition.
b. Recognition itself is an indication that an object belongs to a certain class.
2. In these tasks, you can introduce the concept of analogy or similarity of objects and formulate the concept of proximity of objects as a basis for classifying objects into the same class or different classes.
3. In these tasks, you can operate with a set of precedents - examples, the classification of which is known and which in the form of formalized descriptions can be presented to the recognition algorithm to adjust to the task during the learning process.
4. For these problems it is difficult to build formal theories and apply classical mathematical methods: often information for an accurate mathematical model or gain from using the model and mathematical methods incommensurate with the costs.
5. In these tasks, “bad information” is possible - information with omissions, heterogeneous, indirect, fuzzy, ambiguous, probabilistic.
It is advisable to distinguish the following types of recognition tasks:
1. Recognition task, that is, assigning a presented object according to its description to one of the given classes (supervised learning).
2. The task of automatic classification is the division of a set of objects (situations) according to their descriptions into a system of non-overlapping classes (taxonomy, cluster analysis, unsupervised learning).
3. The task of selecting an informative set of features during recognition.
4. The task of reducing the source data to a form convenient for recognition.
5. Dynamic recognition and dynamic classification - tasks 1 and 2 for dynamic objects.
6. Forecasting problem - problems 5 in which the decision must relate to some point in the future.
The concept of image.
An image, a class is a classification grouping in a system that unites (selects) a certain group of objects according to a certain criterion. Images have a number of characteristic properties, which manifest themselves in the fact that familiarization with a finite number of phenomena from the same set makes it possible to recognize an arbitrarily large number of its representatives.
A certain set of states of a control object can also be considered as an image, and this entire set of states is characterized by the fact that in order to achieve a given goal, the same impact on the object is required. Images have characteristic objective properties in the sense that different people, trained on different observational material, for the most part classify the same objects in the same way and independently of each other.
In general, the problem of pattern recognition consists of two parts: training and recognition.
Training is carried out by showing individual objects indicating their belonging to one or another image. As a result of training, the recognition system must acquire the ability to respond with the same reactions to all objects of the same image and with different reactions to all objects of different images.
It is very important that the learning process should be completed only by showing a finite number of objects without any other prompts. The objects of learning can be either visual images, or various phenomena of the external world, and others.
Training is followed by the process of recognizing new objects, which characterizes the action of an already trained system. Automation of these procedures is the problem of teaching pattern recognition. In the case when a person himself solves or invents, and then imposes classification rules on a computer, the recognition problem is partially solved, since the person takes on the main and main part of the problem (training).
The problem of teaching pattern recognition is interesting from both an applied and a fundamental point of view. From an applied point of view, solving this problem is important primarily because it opens up the possibility of automating many processes that until now have been associated only with the activity of the living brain. The fundamental significance of the problem is related to the question of what a computer can and cannot do in principle.
When solving control problems using pattern recognition methods, the term “state” is used instead of the term “image”. State – certain forms of displaying the measured current (instantaneous) characteristics of the observed object; a set of states determines the situation.
A situation is usually called a certain set of states of a complex object, each of which is characterized by the same or similar characteristics of the object. For example, if a certain control object is considered as an object of observation, then the situation combines such states of this object in which the same control actions should be applied. If the object of observation is a game, then the situation unites all states of the game.
The choice of the initial description of objects is one of the central tasks of the problem of learning pattern recognition. If the initial description (feature space) is successfully chosen, the recognition task may turn out to be trivial. Conversely, a poorly chosen initial description can lead to either very difficult further processing of information or no solution at all.
Geometric and structural approaches.
Any image that arises as a result of observing an object during training or an exam can be represented as a vector, and therefore as a point in some feature space.
If it is stated that when images are shown it is possible to unambiguously attribute them to one of two (or several) images, then it is thereby stated that in some space there are two or more regions that do not have common points, and that the image of a point is from these regions. Each point in such an area can be assigned a name, that is, a name corresponding to the image can be given.
Let us interpret the process of learning pattern recognition in terms of a geometric picture, limiting ourselves for now to the case of recognizing only two images. It is considered known in advance only that it is necessary to separate two regions in some space and that only points from these regions are shown. These areas themselves are not predetermined, that is, there is no information about the location of their boundaries or rules for determining whether a point belongs to a particular area.
During training, points randomly selected from these areas are presented, and information is provided about which area the presented points belong to. No additional information about these areas, that is, the location of their boundaries, is provided during training.
The goal of training is either to construct a surface that would separate not only the points shown during the training process, but also all other points belonging to these areas, or to construct surfaces that limit these areas so that each of them contains only points of one image. In other words, the goal of training is to construct functions from image vectors that would, for example, be positive at all points of one image and negative at all points of another image.
Due to the fact that the areas do not have common points, there is always a whole set of such separating functions, and as a result of training, one of them must be constructed. If the presented images belong not to two, but more images, then the task is to construct, using the points shown during training, a surface separating all the areas corresponding to these images from each other.
This problem can be solved, for example, by constructing a function that takes over the points of each of the areas same value, and over points from different areas the value of this function should be different.
It may seem that knowing just a few points from an area is not enough to isolate the entire area. Indeed, it is possible to indicate an infinite number of different areas that contain these points, and no matter how the surface is constructed from them, highlighting the area, it is always possible to indicate another area that intersects the surface and at the same time contains the shown points.
However, it is known that the problem of approximating a function from information about it in a limited set of points is significantly narrower than the entire set on which the function is given, and is a common mathematical problem of approximating functions. Of course, solving such problems requires introducing certain restrictions on the class of functions under consideration, and the choice of these restrictions depends on the nature of the information that the teacher can add to the teaching process.
One such clue is the hypothesis of compactness of images.
Along with the geometric interpretation of the problem of teaching pattern recognition, there is another approach, which is called structural, or linguistic. Let's consider the linguistic approach using the example of visual image recognition.
First, a set of initial concepts is identified - typical fragments found in the image, and characteristics of the relative position of the fragments (on the left, below, inside, etc.). These initial concepts form a vocabulary that allows you to construct various logical statements, sometimes called sentences.
The task is to select from a large number of statements that could be constructed using these concepts the most significant ones for a given specific case. Next, viewing a finite and possibly small number of objects from each image, you need to construct a description of these images.
The constructed descriptions must be so complete as to resolve the question of which image a given object belongs to. When implementing a linguistic approach, two tasks arise: the task of constructing an initial dictionary, that is, a set of typical fragments, and the task of constructing description rules from elements of a given dictionary.
Within the framework of linguistic interpretation, an analogy is drawn between the structure of images and the syntax of language. The desire for this analogy was caused by the opportunity to use the apparatus of mathematical linguistics, that is, the methods are syntactic in nature. The use of the apparatus of mathematical linguistics to describe the structure of images can be used only after the images have been segmented into their component parts, that is, words have been developed to describe typical fragments and methods for searching for them.
After preliminary work ensuring the selection of words, the actual linguistic tasks arise, consisting of tasks of automatic grammatical parsing of descriptions for image recognition.
Compactness hypothesis.
If we assume that during the learning process, the feature space is formed based on the intended classification, then we can hope that the specification of the feature space itself specifies a property under the influence of which images in this space are easily separated. It was these hopes, as work in the field of pattern recognition developed, that stimulated the emergence of the compactness hypothesis, which states that images correspond to compact sets in the feature space.
By a compact set we mean certain clusters of points in image space, assuming that between these clusters there are rarefactions separating them. However, this hypothesis could not always be confirmed experimentally. But those tasks for which the compactness hypothesis was well fulfilled always found a simple solution, and vice versa, those tasks for which the hypothesis was not confirmed were either not solved at all, or were solved with great difficulty and the involvement of additional information.
The compactness hypothesis itself has become a sign of the possibility of satisfactorily solving recognition problems.
The formulation of the compactness hypothesis brings us close to the concept of an abstract image. If the coordinates of the space are chosen randomly, then the images in it will be distributed randomly. They will be more densely located in some parts of the space than in others.
Let's call some randomly selected space an abstract image. In this abstract space there will almost certainly exist compact sets of points. Therefore, in accordance with the compactness hypothesis, the set of objects to which compact sets of points correspond in an abstract space are usually called abstract images of a given space.
Training and self-learning, adaptation and training.
If it were possible to notice a certain universal property that does not depend either on the nature of images or on their images, but determines only the ability to be separated, then along with the usual task of learning recognition using information about the belonging of each object from the training sequence to one or another image, it is possible It would be possible to pose a different classification problem - the so-called unsupervised learning problem.
A task of this kind at the descriptive level can be formulated as follows: the system is simultaneously or sequentially presented with objects without any indication of their belonging to images. The input device of the system maps a set of objects onto a set of images and, using some property of image separability inherent in it in advance, produces an independent classification of these objects.
After such a self-learning process, the system should acquire the ability to recognize not only already familiar objects (objects from the training sequence), but also those that were not previously presented. The process of self-learning of a certain system is a process as a result of which this system, without prompting from a teacher, acquires the ability to develop identical reactions to images of objects of the same image and different reactions to images of different images.
The role of the teacher in this case is only to suggest to the system some objective property that is the same for all images and determines the ability to divide many objects into images.
It turns out that such an objective property is the property of compactness of images. Mutual arrangement points in the selected space already contains information about how the set of points should be divided. This information determines the property of image separability, which is sufficient for the system to self-learn image recognition.
Most known self-learning algorithms are capable of identifying only abstract images, that is, compact sets in given spaces. The difference between them lies in the formalization of the concept of compactness. However, this does not reduce, and sometimes even increases, the value of self-learning algorithms, since often the images themselves are not defined in advance by anyone, and the task is to determine which subsets of images in a given space represent images.
An example of such a problem statement is sociological research, when groups of people are identified based on a set of questions. In this understanding of the problem, self-learning algorithms generate previously unknown information about the existence of images in a given space that no one previously had any idea about.
In addition, the result of self-learning characterizes the suitability of the selected space for a specific recognition learning task. If the abstract images identified in the self-learning space coincide with real ones, then the space has been chosen well. The more abstract images differ from real ones, the more inconvenient the chosen space is for a specific task.
Learning is usually called the process of developing in a certain system one or another reaction to groups of external identical signals through repeated exposure to the system of external adjustments. The mechanism for generating this adjustment almost completely determines the learning algorithm.
Self-learning differs from training in that here additional information about the correctness of the reaction to the system is not provided.
Adaptation is the process of changing the parameters and structure of the system, and possibly control actions, based on current information in order to achieve a certain state of the system under initial uncertainty and changing operating conditions.
Learning is a process as a result of which the system gradually acquires the ability to respond with the necessary reactions to certain sets of external influences, and adaptation is the adjustment of the parameters and structure of the system in order to achieve the required quality of control in the face of continuous changes in external conditions.
Speech recognition systems.
Speech acts as the main means of communication between people and therefore verbal communication is considered one of the most important components of an artificial intelligence system. Speech recognition is the process of converting an acoustic signal generated at the output of a microphone or telephone into a sequence of words.
A more difficult task is the task of understanding speech, which involves identifying the meaning of an acoustic signal. In this case, the output of the speech recognition subsystem serves as the input of the utterance understanding subsystem. Automatic speech recognition (ARR systems) is one of the areas of processing technologies natural language.
Automatic speech recognition is used to automate text entry into a computer, when generating oral queries to databases or information retrieval systems, when generating verbal commands to various intelligent devices.
Basic concepts of speech recognition systems.
Speech recognition systems are characterized by many parameters.
One of the main parameters is the word recognition error (WOR). This parameter is the ratio of the number of unrecognized words to the total number of spoken words.
Other parameters characterizing automatic speech recognition systems are:
1) dictionary size,
2) speech mode,
3) speech style,
4) subject area,
5) speaker addiction,
6) acoustic noise level,
7) quality of the input channel.
Depending on the size of the dictionary, APP systems are divided into three groups:
With a small dictionary size (up to 100 words),
With an average vocabulary size (from 100 words to several thousand words),
With a large dictionary size (more than 10,000 words).
Speech mode characterizes the way words and phrases are pronounced. There are systems for recognizing continuous speech and systems that allow recognizing only isolated words of speech. Isolated word recognition mode requires the speaker to pause briefly between words.
According to the style of speech, APP systems are divided into two groups: deterministic speech systems and spontaneous speech systems.
In deterministic speech recognition systems, the speaker reproduces speech following the grammatical rules of the language. Spontaneous speech is characterized by disturbances grammar rules and it is more difficult to recognize.
Depending on the subject area, APP systems are distinguished that are focused on application in highly specialized areas (for example, access to databases) and APP systems with an unlimited scope of application. The latter require a large vocabulary and must provide recognition of spontaneous speech.
Many automatic speech recognition systems are speaker-dependent. This involves pre-tuning the system to the pronunciation features of a particular speaker.
The complexity of solving the problem of speech recognition is explained by the large variability of acoustic signals. This variability is due to several reasons:
Firstly, by the different implementation of phonemes - the basic units of the sound structure of a language. Variability in the implementation of phonemes is caused by the influence of neighboring sounds in the speech stream. Shades of the realization of phonemes, determined by the sound environment, are called allophones.
Secondly, the position and characteristics of the acoustic receivers.
Thirdly, changes in the speech parameters of the same speaker, which are caused by different emotional state announcer, the pace of his speech.
The figure shows the main components of the speech recognition system:
The digitized speech signal is sent to a pre-processing unit, where the features necessary for sound recognition are extracted. Sound recognition is often done using artificial neural network models. The selected sound units are subsequently used to search for a sequence of words that most closely matches the input speech signal.
The search for a sequence of words is performed using acoustic, lexical and language models. Model parameters are determined from training data based on appropriate learning algorithms.
Speech synthesis from text. Basic Concepts
In many cases, the creation of artificial intelligence systems with elements of self-communication requires the output of messages in speech form. The figure shows structural scheme intelligent question-answer system with speech interface:
Picture 1.
Take a piece of lectures from Oleg
Let us consider the features of the empirical approach using the example of part-of-speech recognition. The task is to assign labels to the words of the sentence: noun, verb, preposition, adjective, and the like. In addition, it is necessary to determine some additional features of nouns and verbs. For example, for a noun - a number, and for a verb - a form. Let's formalize the problem.
Let's imagine a sentence as a sequence of words: W=w1 w2…wn, where wn are random variables, each of which receives one of the possible values belonging to the language dictionary. The sequence of labels assigned to the words of a sentence can be represented by the sequence X=x1 x2 ... xn, where xn are random variables whose values are determined on the set of possible labels.
Then the task of part-of-speech recognition is to find the most probable sequence of labels x1, x2, ..., xn from a given sequence of words w1, w2, ..., wn. In other words, it is necessary to find a sequence of labels X*=x1 x2 … xn that provides the maximum conditional probability P(x1, x2, …, xn| w1 w2.. wn).
Let us rewrite the conditional probability P(X| W) in the following form P(X| W)=P(X,W) / P(W). Since it is required to find the maximum of the conditional probability P(X,W) for the variable X, we obtain X*=arg x max P(X,W). The joint probability P(X,W) can be written as a product of conditional probabilities: P(X,W)=product of u-1 to n from P(x i |x1,…,x i -1 , w1,…,wi -1 ) P(w i |x1,…,x i -1 , w1,…,w i -1). A direct search for the maximum of a given expression is difficult task, since for large values of n the search space becomes very large. Therefore, the probabilities that are written in this product are approximated by simpler conditional probabilities: P(x i |x i -1) P(w i |w i -1). In this case, it is assumed that the value of the label x i is associated only with the previous label x i -1 and does not depend on earlier labels, and also that the probability of the word w i is determined only by the current label x i . These assumptions are called Markov assumptions, and to solve the problem the theory of Markov models is used. Taking into account the Markov assumptions, we can write:
X*= arg x1, …, xn max P i =1 n P(x i |x i -1) P(wi|wi-1)
Where conditional probabilities are estimated on a set of training data
The search for a sequence of labels X* is carried out using the Viterbi dynamic programming algorithm. The Viterbi algorithm can be considered as a variant of the search algorithm on a state graph, where the vertices correspond to word labels.
It is characteristic that for any current vertex the set of child labels is always the same. Moreover, for each child vertex, the sets of parent vertices also coincide. This is explained by the fact that transitions are carried out on the state graph taking into account all possible combinations of labels. Markov's assumptions provide a significant simplification of the problem of recognizing parts of speech while maintaining high accuracy in assigning labels to words.
Thus, with 200 labels, the assignment accuracy is approximately 97%. For a long time, imperial analysis was performed using stochastic context-free grammars. However, they have a significant drawback. It lies in the fact that different grammatical parses can be assigned the same probabilities. This occurs because the parsing probability is represented as the product of the probabilities of the rules involved in the parsing. If during the analysis different rules are used, characterized by the same probabilities, then this gives rise to the indicated problem. top scores is given by a grammar that takes into account the vocabulary of the language.
In this case, the rules include the necessary lexical information that provides different meanings probabilities for the same rule in different lexical environments. Imperial parsing is more consistent with pattern recognition than with traditional grammatical parsing in its classical sense.
Comparative studies have shown that the accuracy of imperial parsing in natural language applications is higher than that of traditional parsing.