Системы распознавания образов примеры. Общая характеристика задач распознавания образов и их типы. Методы распознавания образов
В целом, можно выделить три метода распознавания образов: Метод перебора. В этом случае производится сравнение с базой данных, где для каждого вида объектов представлены всевозможные модификации отображения. Например, для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д. В случае распознавания звуковых образов, соответственно, происходит сравнение с некоторыми известными шаблонами (например, слово, произнесенное несколькими людьми).
Второй подход - производится более глубокий анализ характеристик образа. В случае оптического распознавания это может быть определение различных геометрических характеристик. Звуковой образец в этом случае подвергается частотному, амплитудному анализу и т. д.
Следующий метод - использование искусственных нейронных сетей (ИНС). Этот метод требует либо большого количества примеров задачи распознавания при обучении, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее, его отличает более высокая эффективность и производительность.
4. История распознавания образов
Рассмотрим кратко математический формализм распознавания образов. Объект в распознавании образов описывается совокупностью основных характеристик (признаков, свойств). Основные характеристики могут иметь различную природу: они могут браться из упорядоченного множества типа вещественной прямой, либо из дискретного множества (которое, впрочем, так же может быть наделено структурой). Такое понимание объекта согласуется как потребностью практических приложений распознавания образов, так и с нашим пониманием механизма восприятия объекта человеком. Действительно, мы полагаем, что при наблюдении (измерении) объекта человеком, сведения о нем поступают по конечному числу сенсоров (анализируемых каналов) в мозг, и каждому сенсору можно сопоставить соответствующую характеристику объекта. Помимо признаков, соответствующих нашим измерениям объекта, существует так же выделенный признак, либо группа признаков, которые мы называем классифицирующими признаками, и в выяснении их значений при заданном векторе Х и состоит задача, которую выполняют естественные и искусственные распознающие системы.
Понятно, что для того, чтобы установить значения этих признаков, необходимо иметь информацию о том, как связаны известные признаки с классифицирующими. Информация об этой связи задается в форме прецедентов, то есть множества описаний объектов с известными значениями классифицирующих признаков. И по этой прецедентной информации и требуется построить решающее правило, которое будет ставить произвольному описанию объекта значения его классифицирующих признаков.
Такое понимание задачи распознавания образов утвердилось в науке начиная с 50-х годов прошлого века. И тогда же было замечено что такая постановка вовсе не является новой. С подобной формулировкой сталкивались и уже существовали вполне не плохо зарекомендовавшие себя методы статистического анализа данных, которые активно использовались для многих практических задач, таких как например, техническая диагностика. Поэтому первые шаги распознавания образов прошли под знаком статистического подхода, который и диктовал основную проблематику.
Статистический подход основывается на идее, что исходное пространство объектов представляет собой вероятностное пространство, а признаки (характеристики) объектов являют собой случайные величины заданные на нем. Тогда задача исследователя данных состояла в том, чтобы из некоторых соображений выдвинуть статистическую гипотезу о распределении признаков, а точнее о зависимости классифицирующих признаков от остальных. Статистическая гипотеза, как правило, представляла собой параметрически заданное множество функций распределения признаков. Типичной и классической статистической гипотезой является гипотеза о нормальности этого распределения (разновидностей таких гипотез статистики придумали великое множество). После формулировки гипотезы оставалось проверить эту гипотезу на прецедентных данных. Это проверка состояла в выборе некоторого распределения из первоначально заданного множества распределений (параметра гипотезы о распределении) и оценки надежности(доверительного интервала) этого выбора. Собственно эта функция распределения и была ответом к задаче, только объект классифицировался уже не однозначно, но с некоторыми вероятностями принадлежности к классам. Статистиками были разработано так же и ассимптотическое обоснование таких методов. Такие обоснования делались по следующей схеме: устанавливался некоторый функционал качества выбора распределения (доверительный интервал) и показывалось, что при увеличении числа прецедентов, наш выбор с вероятностью стремящейся к 1 становился верным в смысле этого функционала (доверительный интервал стремился к 0). Забегая вперед скажем, что статистический взгляд на проблему распознавания оказался весьма плодотворным не только в смысле разработанных алгоритмов (в число которых входят методы кластерного, дискриминантного анализов, непараметрическая регрессия и т.д.), но и привел впоследствии Вапника к созданию глубокой статистической теории распознавания.
Тем не менее существует серьезная аргументация в пользу того, что задачи распознавания образов не сводятся к статистике. Любую такую задачу, в принципе, можно рассматривать со статистической точки зрения и результаты ее решения могут интерпретироваться статистически. Для этого необходимо лишь предположить, что пространство объектов задачи является вероятностным. Но с точки зрения инструментализма, критерием удачности статистической интерпретации некоторого метода распознавания может служить лишь наличие обоснавания этого метода на языке статистики как раздела математики. Под обоснаванием здесь понимается выработка основных требований к задаче которые обеспечивают успех в применении этого метода. Однако на данный момент для большей части методов распознавания, в том числе и для тех, которые напрямую возникли в рамках статистического подхода, подобных удовлетворительных обоснований не найдено. Кроме этого, наиболее часто применяемые на данный момент статистические алгоритмы, типа линейного дискриминанта Фишера, парзеновского окна, EM-алгоритма, метода ближайших соседей, не говоря уже о байесовских сетях доверия, имеют сильно выраженный эвристический характер и могут иметь интерпретации отличные от статистических. И наконец, ко всему вышесказанному следует добавить, что помимо асимптотического поведения методов распознавания, которое и является основным вопросом статистики, практика распознавания ставит вопросы вычислительной и структурной сложности методов, которые выводят далеко за рамки одной лишь теории вероятностей.
Итого, вопреки стремлениям статистиков рассматривать распознавание образов как раздел статистики, в практику и идеологию распознавания входили совершенно другие идеи. Одна из них была вызвана исследованиями в области распознавания зрительных образов и основана на следующей аналогии.
Как уже отмечалось, в повседневной жизни люди постоянно решают (зачастую бессознательно) проблемы распознавания различных ситуаций, слуховых и зрительных образов. Подобная способность для ЭВМ представляет собой в лучшем случае дело будущего. Отсюда некоторыми пионерами распознавания образов был сделан вывод, что решение этих проблем на ЭВМ должно в общих чертах моделировать процессы человеческого мышления. Наиболее известной попыткой подойти к проблеме с этой стороны было знаменитое исследование Ф. Розенблатта по перцептронам .
К середине 50-х годов казалось, что нейрофизиологами были поняты физические принципы работы мозга (в книге "Новый Разум Короля" знаменитый британский физик-теоретик Р. Пенроуз интересно ставит под сомнение нейросетевую модель мозга, обосновывая существенную роль в его функционировании квантово-механических эффектов; хотя, впрочем, эта модель подвергалась сомнению с самого начала. Отталкиваясь от этих открытий Ф.Розенблатт разработал модель обучения распознаванию зрительных образов, названную им персептроном. Персептрон Розенблатта представляет собой следующую функцию (рис. 1):
Рис 1. Схема Персептрона
На входе персептрон получает вектор объекта, который в работах Розенблатта представлял собой бинарный вектор, показывавший какой из пикселов экрана зачернен изображением а какой нет. Далее каждый из признаков подается на вход нейрона, действие которого представляет собой простое умножение на некоторый вес нейрона. Результаты подаются на последний нейрон, который их складывает и общую сумму сравнивает с некоторым порогом. В зависимости от результатов сравнения входной объект Х признается нужным образом либо нет. Тогда задача обучения распознаванию образов состояла в таком подборе весов нейронов и значения порога, чтобы персептрон давал на прецедентных зрительных образах правильные ответы. Розенблатт полагал, что получившаяся функция будет неплохо распознавать нужный зрительный образ даже если входного объекта и не было среди прецедентов. Из бионических соображений им так же был придуман и метод подбора весов и порога, на котором останавливаться мы не будем. Скажем лишь, что его подход оказался успешным в ряде задач распознавания и породил собой целое направление исследований алгоритмов обучения основанных на нейронных сетях, частным случаем которых и является персептрон.
Далее были придуманы различные обобщения персептрона, функция нейронов была усложнена: нейроны теперь могли не только умножать входные числа или складывать их и сравнивать результат с порогами, но применять по отношению к ним более сложные функции. На рисунке 2 изображено одно из подобных усложнений нейрона:

Рис. 2 Схема нейронной сети.
Кроме того топология нейронной сети могла быть значительно сложнее той, что рассматривал Розенблатт, например такой:
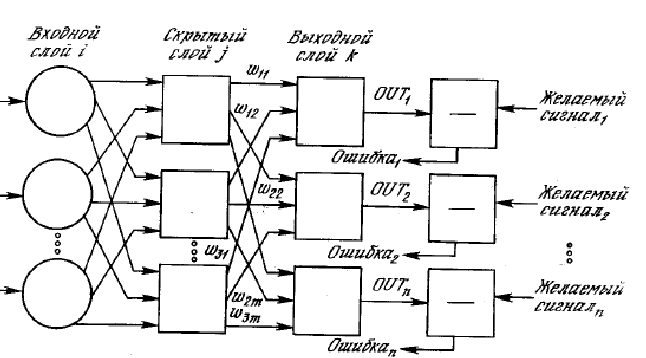
Рис. 3. Схема нейронной сети Розенблатта.
Усложнения приводили к увеличению числа настраиваемых параметров при обучении, но при этом увеличивали возможность настраиваться на очень сложные закономерности. Исследования в этой области сейчас идут по двум тесно связанным направлениям - изучаются и различные топологии сетей и различные методы настроек.
Нейронные сети на данный момент являются не только инструментом решения задач распознавания образов, но получили применение в исследованиях по ассоциативной памяти, сжатию изображений. Хотя это направление исследований и пересекается сильно с проблематикой распознавания образов, но представляет собой отдельный раздел кибернетики. Для распознавателя на данный момент, нейронные сети не более чем очень специфически определенное, параметрически заданное множество отображений, которое в этом смысле не имеет каких-либо существенных преимуществ над многими другим подобными моделями обучения которые далее будут кратко перечислены.
В связи с данной оценкой роли нейронных сетей для собственно распознавания (то есть не для бионики, для которой они имеют первостепенное значение уже сейчас) хотелось бы отметить следующее: нейронные сети, будучи чрезвычайно сложным объектом для математического анализа, при грамотном их использовании, позволяют находить весьма нетривиальные законы в данных. Их трудность для анализа, в общем случае, объясняется их сложной структурой и как следствие, практически неисчерпаемыми возможностями для обобщения самых различных закономерностей. Но эти достоинства, как это часто и бывает, являются источником потенциальных ошибок, возможности переобучения. Как будет рассказано далее, подобный двоякий взгляд на перспективы всякой модели обучения является одним из принципов машинного обучения.
Еще одним популярным направлением в распознавании являются логические правила и деревья решений. В сравнении с вышеупомянутыми методами распознавания эти методы наиболее активно используют идею выражения наших знаний о предметной области в виде, вероятно самых естественных (на сознательном уровне) структур - логических правил. Под элементарным логическим правилом подразумевается высказывание типа «если неклассифицируемые признаки находятся в соотношении X то классифицируемые находятся в соотношении Y». Примером такого правила в медицинской диагностике служит следующее: если возраст пациента выше 60 лет и ранее он перенёс инфаркт, то операцию не делать - риск отрицательного исхода велик.
Для поиска логических правил в данных необходимы 2 вещи: определить меру «информативности» правила и пространство правил. И задача поиска правил после этого превращается в задачу полного либо частичного перебора в пространстве правил с целью нахождения наиболее информативных из них. Определение информативности может быть введено самыми различными способами и мы не будем останавливаться на этом, считая что это тоже некоторый параметр модели. Пространство же поиска определяется стандартно.
После нахождения достаточно информативных правил наступает фаза «сборки» правил в конечный классификатор. Не обсуждая глубоко проблемы которые здесь возникают (а их возникает немалое количество) перечислим 2 основных способа «сборки». Первый тип - линейный список. Второй тип – взвешенное голосование, когда каждому правилу ставится в соответствие некоторый вес, и объект относится классификатором к тому классу за который проголосовало наибольшее количество правил.
В действительности, этап построения правил и этап «сборки» выполняются сообща и, при построении взвешенного голосования либо списка, поиск правил на частях прецедентных данных вызывается снова и снова, чтобы обеспечить лучшее согласование данных и модели.
Аннотация: Мы хотим прийти к пониманию феномена мышления, идя от задач поведения и восприятия, т. е. от задач, для решения которых возник и эволюционно развивался мозг. В предыдущих лекциях мы говорили о поведении. Теперь посмотрим, что дает для понимания феномена мышления задача восприятия. Мы рассмотрим некоторые принципы "интеллектуального" восприятия, конкретизирующиеся на примере решения задачи автоматического чтения рукописных символов. Практическая ориентация не привела, как это часто бывает, к упрощению и выхолащиванию проблемы восприятия. Наоборот, для получения работоспособного решения потребовалось введение "интеллектуальных" составляющих, ориентированных на распознавание "с пониманием".
Распознавание образов
С самого начала развития кибернетики машинное восприятие изображений чаще всего выбиралось для исследования и моделирования интеллекта и, в частности, таких очевидных составляющих мышления, как построение системы обобщенных знаний о среде и использование этих знаний в процессе принятия решений . Восприятие зрительной информации представлялось наиболее удобным для моделирования и в то же время наиболее практически значимым.
Сразу было ясно, что для полного решения задачи машинного зрительного восприятия необходимо "интеллектуальное" распознавание , или распознавание "с пониманием". Часто даже пытались сводить мышление к восприятию, попросту ставя между ними знак тождества. В дальнейшем мы увидим, что мышление и восприятие неразрывно связаны, но это далеко не одно и то же. Поэтому исследования живого восприятия (в первую очередь зрительного), безусловно, полезны для понимания процесса мышления, но проблему в целом далеко не решают. В то же время практическая ориентация работ в области автоматического анализа зрительной информации и стремление к технической реализуемости привели к серьезной трансформации проблемы. Оказалось практически почти вынужденным упрощенное рассмотрение процесса восприятия путем сведения его к классификации по признакам простых объектов, рассматриваемых по отдельности. Это направление стало называться " Распознавание образов ".
Распознавание образов к направлению " Искусственный интеллект " (ИИ) чаще всего не относили, поскольку в отличие от задач ИИ в распознавании образов появился хорошо разработанный математический аппарат, и для не очень сложных объектов, оказалось возможным строить практически работающие системы распознавания (классификации). В результате традиционное распознавание образов , с одной стороны, не решает задачу машинного анализа сложных изображений и, с другой стороны, не является серьезным инструментом для моделирования интеллекта. Рассмотрим связанные с этим вопросы более подробно.
Для любого распознавания нужны эталоны или модели классов распознаваемых объектов. Классификация методов распознавания возможна по типам используемых эталонов или, что почти то же самое, по способу представления объектов на входе распознающей системы. В большинстве систем распознавания изображений обычно применяются растровый, признаковый или структурный методы.
Растровому подходу соответствуют эталоны, являющиеся изображениями либо какими-то препаратами изображений. При распознавании представленное в виде точечного растра входное изображение сопоставляется точка в точку со всеми эталонными и определяется, с каким из эталонов изображение совпадает лучше, например, имеет больше общих точек. Входное и эталонное изображения должны быть одного размера и одной ориентации. Например, в так называемых multifont-OCR (многошрифтовых распознавателях печатного текста) это достигается построением разных эталонов не только для разных шрифтов, но и для разных размеров символов (кеглей) в пределах одного шрифта. Распознавание таким способом рукописных символов невозможно ввиду их слишком большой вариабельности по форме, размеру и ориентации.
Возможен также вариант использования растрового распознавания с приведением входного изображения к стандартным размерам и ориентации. В этом случае распознавание рукописных символов растровым методом становится возможным после кластеризации каждого распознаваемого класса и создания отдельного растрового эталона для каждого кластера.
В общем случае получение инвариантности по отношению к размерам, форме и ориентации распознаваемых по растру объектов является сложной, а часто и неразрешимой проблемой. Другую проблему порождает необходимость выделения из изображения его фрагмента, относящегося к отдельному объекту. Эта проблема является общей для всех классических методов распознавания образов.
В подавляющем большинстве систем распознавания и, в частности, в существующих omnifont -системах оптического чтения основным является признаковый метод. При признаковом подходе эталоны строятся с использованием выделяемых на изображении признаков. Изображение на входе распознающей системы представляется вектором признаков. В качестве признаков может рассматриваться все что угодно - любые характеристики распознаваемых объектов. Признаки должны быть инвариантны к ориентации, размеру и вариациям формы объектов. Желательно также, чтобы векторы признаков, относящиеся к разным объектам одного класса, принадлежали выпуклой компактной области пространства признаков. Пространство признаков должно быть фиксировано и одинаково для всех распознаваемых объектов. Алфавит признаков придумывается разработчиком системы. Качество распознавания во многом зависит от того, насколько удачно придуман алфавит признаков. Какого-либо общего способа автоматического построения оптимального алфавита признаков не существует.
Распознавание состоит в априорном получении полного вектора признаков для любого выделенного на изображении отдельного распознаваемого объекта и лишь затем в определении того, какому из эталонов этот вектор соответствует. Эталоны чаще всего строятся как статистические либо как геометрические объекты. В первом случае обучение может состоять, например, в получении матрицы частот появления каждого признака в каждом классе объектов, а распознавание - в определении вероятностей принадлежности вектора признаков каждому из эталонов.
При геометрическом подходе результатом обучения чаще всего является разбиение пространства признаков на области, соответствующие разным классам распознаваемых объектов, а распознавание состоит в определении того, в какую из этих областей попадает соответствующий распознаваемому объекту входной вектор признаков. Затруднения при отнесении входного вектора признаков к какой-либо области могут возникать в случае пересечения областей, а также если области, соответствующие отдельным распознаваемым классам, не выпуклы и так расположены в пространстве признаков, что распознаваемый класс от других классов одной гиперплоскостью, не отделяется. Эти проблемы решаются чаще всего эвристически, например, за счет вычисления и сравнения расстояний (необязательно евклидовых) в пространстве признаков от экзаменуемого объекта до центров тяжести подмножеств обучающей выборки, соответствующих разным классам. Возможны и более радикальные меры, например, изменение алфавита признаков или кластеризация обучающей выборки, или то и другое одновременно.
Структурному подходу соответствуют эталонные описания, строящиеся в терминах структурных частей объектов и пространственных отношений между ними. Структурные элементы выделяются, как правило, на контуре или на "скелете" объекта. Чаще всего структурное описание может быть представлено графом, включающим структурные элементы и отношения между ними. При распознавании строится структурное описание входного объекта. Это описание сопоставляется со всеми структурными эталонами, например, отыскивается изоморфизм графов.
Растровый и структурный методы иногда сводят к признаковому подходу, рассматривая в первом случае в качестве признаков точки изображения, а во втором - структурные элементы и отношения между ними. Сразу заметим, что между этими методами есть очень важное принципиальное различие. Растровый метод обладает свойством целостности. Структурный метод может обладать свойством целостности. Признаковый метод свойством целостности не обладает.
Что такое целостность , и какую роль она играет при восприятии?
Классическое распознавание образов обычно организуется как последовательный процесс, разворачивающийся "снизу вверх" (от изображения к пониманию) при отсутствии управления восприятием с верхних понятийных уровней. Этапу распознавания предшествует этап получения априорного описания входного изображения. Операции выделения элементов этого описания, например, признаков, или структурных элементов, выполняются на изображении локально, части изображения получают независимую интерпретацию, то есть отсутствует целостное восприятие, что в общем случае может приводить к ошибкам - рассматриваемый изолированно фрагмент изображения часто можно интерпретировать совершенно по -разному в зависимости от гипотезы восприятия, т. е. от того, какой целостный объект предполагается увидеть.
Во-вторых, традиционные подходы ориентированы на распознавание (классификацию) объектов, рассматриваемых по отдельности. Этапу собственно распознавания должен предшествовать этап сегментации (разбиения) изображения на части, соответствующие изображениям отдельных распознаваемых объектов. Методы априорной сегментации обычно используют специфические свойства входного изображения. Общего решения задачи предварительной сегментации не существует. За исключением самых простых случаев, критерий разделения не может быть сформулирован в терминах локальных свойств самого изображения, т. е. до его распознавания.
Строчный, даже рукописный текст не является самым сложным случаем, но и для таких изображений выделение строк, слов и отдельных символов в словах может оказаться серьезной проблемой. Практическое решение этой проблемы часто основывается на переборе вариантов сегментации, и это совершенно не похоже на то, что делает мозг человека или животного в процессе целостного целенаправленного зрительного восприятия. Вспомним сказанное Сеченовым: "Мы не слышим и видим, а слушаем и смотрим". Для такого активного восприятия необходимы целостные представления объектов всех уровней - от отдельных частей до полных сцен - и интерпретация частей только в составе целого.
Таким образом, недостатки большинства традиционных подходов и в первую очередь признакового подхода - это отсутствие целостности восприятия, отсутствие целенаправленности и последовательная однонаправленная организация процесса "снизу вверх", или от изображения к "пониманию".
Распознавание возможно также с использованием окутанных чуть ли не мистическим туманом искусственных или формальных распознающих нейронных сетей (РНС). Иногда их рассматривают даже как какой-то аналог мозга. В последнее время в текстах просто пишут "нейронные сети", опуская прилагательные "искусственный" или "формальный". На самом деле РНС - это чаще всего просто признаковый классификатор , строящий разделяющие гиперплоскости в пространстве признаков.
Используемый в этих сетях формальный нейрон - это сумматор с пороговым элементом, подсчитывающий сумму произведений значений признаков на некоторые коэффициенты , являющиеся не чем иным, как коэффициентами уравнения разделяющей гиперплоскости в пространстве признаков. Если сумма меньше порога, то вектор признаков находится по одну сторону от разделяющей плоскости, если больше - по другую. Вот и все. Кроме построения разделяющих гиперплоскостей и классификации по признакам, никаких чудес.
Введение в формальном нейроне вместо порогового скачка от - 1 к 1 плавного (дифференцируемого), чаще всего сигмаобразного перехода ничего принципиально не меняет, а лишь позволяет использовать градиентные алгоритмы обучения сети, то есть нахождения коэффициентов в уравнениях разделяющих плоскостей, и делать "размазывание" разделяющей границы, присваивая результату распознавания, то есть работе формального нейрона вблизи границы, оценку, например, в диапазоне от 0 до 1. Эта оценка в определенной степени может отражать "уверенность" системы в отнесении входного вектора к той или иной из разделяемых областей пространства признаков. В то же время эта оценка, строго говоря, не является ни вероятностью, ни расстоянием до разделяющей плоскости.
Сеть из формальных нейронов может также аппроксимировать плоскостями нелинейные разделяющие поверхности и объединять по результату несвязанные области пространства признаков. Это и делается в многослойных сетях.
Во всех случаях признаковая распознающая формальная нейронная сеть (ПРНС) - это признаковый классификатор , строящий разделяющие гиперплоскости и выделяющий области в фиксированном пространстве признаков (характеристик). Никаких других задач ПРНС решать не может, причем задачу распознавания ПРНС решает не лучше обычных признаковых распознавателей, использующих аналитические методы.
Кроме того, помимо признаковых распознавателей на формальных нейронах могут строиться растровые, в том числе ансамблевые распознаватели. В этом случае сохраняются все отмеченные недостатки растровых распознавателей. Правда, могут быть и некоторые преимущества, о которых мы еще будем говорить в дальнейшем.
Во избежание недоразумений следует заметить, что на формальных нейронах в принципе можно построить универсальный компьютер , с использованием как разделяющих плоскостей в пространстве переменных, так и легко реализуемых на формальных нейронах логических функций И , ИЛИ и НЕ , однако таких компьютеров никто не строит и обсуждение связанных с этим вопросов выходит за рамки рассматриваемых проблем. Нейрокомпьюторами обычно называют либо просто нейронный распознаватель , либо специальные системы, решающие задачи, близкие распознаванию образов и фактически использующие распознавание на основе построения разделяющих гиперплоскостей в пространстве признаков или на основе сравнения растра с эталоном.
Выше уже отмечалось, что для моделирования мышления очень важно, а может быть, и необходимо понять, как работают нейронные механизмы живого мозга. В связи с этим возникает вопрос: а не являются ли формальные распознающие нейронные сети если и не решением проблемы моделирования нейронных механизмов мозга, то хотя бы важным шагом в этом направлении? К сожалению, ответ должен быть отрицательным. В отличие от активной живой нейронной сети РИС - это пассивный признаковый или растровый классификатор со всеми недостатками традиционных классификаторов. Аргументы, на основании которых сделан этот вывод , более подробно мы рассмотрим в дальнейшем.
Итак, традиционные, в первую очередь признаковые, системы распознавания, основывающиеся на последовательной организации процесса распознавания и классификации объектов, рассматриваемых по отдельности, эффективно решать задачи восприятия сложной зрительной информации не могут, главным образом по причине отсутствия целостности и целенаправленности восприятия, отсутствия целостности в описаниях (эталонах) распознаваемых объектов и последовательной организации процесса распознавания. По этой же причине такие системы распознавания образов мало что дают для понимания живого зрительного восприятия и процесса мышления.
С задачей распознавания образов живые системы, в том числе и человек, сталкиваются постоянно с момента своего появления. В частности, информация, поступающая с органов чувств, обрабатывается мозгом, который в свою очередь сортирует информацию, обеспечивает принятие решения, а далее с помощью электрохимических импульсов передает необходимый сигнал далее, например, органам движения, которые реализуют необходимые действия. Затем происходит изменение окружающей обстановки, и вышеуказанные явления происходят заново. И если разобраться, то каждый этап сопровождается распознаванием.
С развитием вычислительной техники стало возможным решить ряд задач, возникающих в процессе жизнедеятельности, облегчить, ускорить, повысить качество результата. К примеру, работа различных систем жизнеобеспечения, взаимодействие человека с компьютером, появление роботизированных систем и др. Тем не менее, отметим, что обеспечить удовлетворительный результат в некоторых задачах (распознавание быстродвижущихся подобных объектов, рукописного текста) в настоящее время не удается.
Цель работы: изучить историю систем распознавания образов.
Указать качественные изменения произошедшие в области распознавания образов как теоретические, так и технические, с указанием причин;
Обсудить методы и принципы, применяемые в вычислительной технике;
Привести примеры перспектив, которые ожидаются в ближайшем будущем.
1. Что такое распознавание образов?
Первые исследования с вычислительной техникой в основном следовали классической схеме математического моделирования - математическая модель, алгоритм и расчет. Таковыми были задачи моделирования процессов происходящих при взрывах атомных бомб, расчета баллистических траекторий, экономических и прочих приложений. Однако помимо классических идей этого ряда возникали и методы основанные на совершенно иной природе, и как показывала практика решения некоторых задач, они зачастую давали лучший результат нежели решения, основанные на переусложненных математических моделях. Их идея заключалась в отказе от стремления создать исчерпывающую математическую модель изучаемого объекта (причем зачастую адекватные модели было практически невозможно построить), а вместо этого удовлетвориться ответом лишь на конкретные интересующие нас вопросы, причем эти ответы искать из общих для широкого класса задач соображений. К исследованиям такого рода относились распознавание зрительных образов, прогнозирование урожайности, уровня рек, задача различения нефтеносных и водоносных пластов по косвенным геофизическим данным и т. д. Конкретный ответ в этих задачах требовался в довольно простой форме, как например, принадлежность объекта одному из заранее фиксированных классов. А исходные данные этих задач, как правило, задавались в виде обрывочных сведений об изучаемых объектах, например в виде набора заранее расклассифицированных объектов. С математической точки зрения это означает, что распознавание образов (а так и был назван в нашей стране этот класс задач) представляет собой далеко идущее обобщение идеи экстраполяции функции.
Важность такой постановки для технических наук не вызывает никаких сомнений и уже это само по себе оправдывает многочисленные исследования в этой области. Однако задача распознавания образов имеет и более широкий аспект для естествознания (впрочем, было бы странно если нечто столь важное для искусственных кибернетических систем не u1080 имело бы значения для естественных). В контекст данной науки органично вошли и поставленные еще древними философами вопросы о природе нашего познания, нашей способности распознавать образы, закономерности, ситуации окружающего мира. В действительности, можно практически не сомневаться в том, что механизмы распознавания простейших образов, типа образов приближающегося опасного хищника или еды, сформировались значительно ранее, чем возник элементарный язык и формально-логический аппарат. И не вызывает никаких сомнений, что такие механизмы достаточно развиты и у высших животных, которым так же в жизнедеятельности крайне необходима способность различения достаточно сложной системы знаков природы. Таким образом, в природе мы видим, что феномен мышления и сознания явно базируется на способностях к распознаванию образов и дальнейший прогресс науки об интеллекте непосредственно связан с глубиной понимания фундаментальных законов распознавания. Понимая тот факт, что вышеперечисленные вопросы выходят далеко за рамки стандартного определения распознавания образов (в англоязычной литературе более распространен термин supervised learning), необходимо так же понимать, что они имеют глубокие связи с этим относительно узким(но все еще далеко неисчерпанным) направлением .
Уже сейчас распознавание образов плотно вошло в повседневную жизнь и является одним из самых насущных знаний современного инженера. В медицине распознавание образов помогает врачам ставить более точные диагнозы, на заводах оно используется для прогноза брака в партиях товаров. Системы биометрической идентификации личности в качестве своего алгоритмического ядра так же основаны на результатах этой дисциплины. Дальнейшее развитие искусственного интеллекта, в частности проектирование компьютеров пятого поколения, способных к более непосредственному общению с человеком на естественных для людей языках и посредством речи, немыслимы без распознавания. Здесь рукой подать и до робототехники, искусственных систем управления, содержащих в качестве жизненно важных подсистем системы распознавания.
Именно поэтому к развитию распознавания образов с самого начала было приковано немало внимания со стороны специалистов самого различного профиля - кибернетиков, нейрофизиологов, психологов, математиков, экономистов и т.д. Во многом именно по этой причине современное распознавание образов само питается идеями этих дисциплин. Не претендуя на полноту (а на нее в небольшом эссе претендовать невозможно) опишем историю распознавания образов, ключевые идеи .
Определения
Прежде, чем приступить к основным методам распознавания образов, приведем несколько необходимых определений.
Распознавание образов (объектов, сигналов, ситуаций, явлений или процессов) - задача идентификации объекта или определения каких-либо его свойств по его изображению (оптическое распознавание) или аудиозаписи (акустическое распознавание) и другим характеристикам.
Одним из базовых является не имеющее конкретной формулировки понятие множества. В компьютере множество представляется набором неповторяющихся однотипных элементов. Слово "неповторяющихся" означает, что какой-то элемент в множестве либо есть, либо его там нет. Универсальное множество включает все возможные для решаемой задачи элементы, пустое не содержит ни одного.
Образ - классификационная группировка в системе классификации, объединяющая (выделяющая) определенную группу объектов по некоторому признаку. Образы обладают характерным свойством, проявляющимся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей. Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты. В классической постановке задачи распознавания универсальное множество разбивается на части-образы. Каждое отображение какого-либо объекта на воспринимающие органы распознающей системы, независимо от его положения относительно этих органов, принято называть изображением объекта, а множества таких изображений, объединенные какими-либо общими свойствами, представляют собой образы.
Методика отнесения элемента к какому-либо образу называется решающим правилом. Еще одно важное понятие - метрика, способ определения расстояния между элементами универсального множества. Чем меньше это расстояние, тем более похожими являются объекты (символы, звуки и др.) - то, что мы распознаем. Обычно элементы задаются в виде набора чисел, а метрика - в виде функции. От выбора представления образов и реализации метрики зависит эффективность программы, один алгоритм распознавания с разными метриками будет ошибаться с разной частотой.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Такую внешнюю корректировку в обучении принято называть "поощрениями" и "наказаниями". Механизм генерации этой корректировки практически полностью определяет алгоритм обучения. Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация - это процесс изменения параметров и структуры системы, а возможно - и управляющих воздействий, на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Обучение - это процесс, в результате которого система постепенно приобретает способность отвечать нужными реакциями на определенные совокупности внешних воздействий, а адаптация - это подстройка параметров и структуры системы с целью достижения требуемого качества управления в условиях непрерывных изменений внешних условий.
Примеры задач распознавания образов: - Распознавание букв;
Образ, класс - классификационная группировка в системе классификации, объединяющая (выделяющая) определенную группу объектов по некоторому признаку.Образное восприятие мира - одно из загадочных свойств живого мозга, позволяющее разобраться в бесконечном потоке воспринимаемой информации и сохранять ориентацию в океане разрозненных данных о внешнем мире. Воспринимая внешний мир, мы всегда производим классификацию воспринимаемых ощущений, т. е. разбиваем их на группы похожих, но не тождественных явлений. Например, несмотря на существенное различие, к одной группе относятся все буквы А, написанные различными почерками, или все звуки, которые соответствуют одной и той же ноте, взятой в любой октаве и на любом инструменте, а оператор, управляющий техническим объектом, на целое множество состояний объекта реагирует одной и той же реакцией. Характерно, что для составления понятия о группе восприятий определенного класса достаточно ознакомиться с незначительным количеством ее представителей. Ребенку можно показать всего один раз какую-либо букву, чтобы он смог найти эту букву в тексте, написанном различными шрифтами, или узнать ее, даже если она написана в умышленно искаженном виде. Это свойство мозга позволяет сформулировать такое понятие, как образ.
Образы обладают характерным свойством, проявляющимся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей. Примерами образов могут быть: река, море, жидкость, музыка Чайковского, стихи Маяковского и т. д. В качестве образа можно рассматривать и некоторую совокупность состояний объекта управления, причем вся эта совокупность состояний характеризуется тем, что для достижения заданной цели требуется одинаковое воздействие на объект . Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты. Именно эта объективность образов позволяет людям всего мира понимать друг друга.
Способность восприятия внешнего мира в форме образов позволяет с определенной достоверностью узнавать бесконечное число объектов на основании ознакомления с конечным их числом, а объективный характер основного свойства образов позволяет моделировать процесс их распознавания. Будучи отражением объективной реальности, понятие образа столь же объективно, как и сама реальность, а поэтому может быть само по себе объектом специального исследования.
В литературе, посвященной проблеме обучения распознавания образов (ОРО), часто вместо понятия образа вводится понятие класса.
Проблема обучения распознаванию образов (ОРО)
Одним из самых интересных свойств человеческого мозга является способность отвечать на бесконечное множество состояний внешней среды конечным числом реакций. Может быть, именно это свойство позволило человеку достигнуть высшей формы существования живой материи, выражающейся в способности к мышлению, т. е. активному отражению объективного мира в виде образов, понятий, суждений и т. д. Поэтому проблема ОРО возникла при изучении физиологических свойств мозга.
Рассмотрим пример задач из области ОРО.
Рис.
3.1.
Здесь представлены 12 изображений, и следует отобрать признаки, при помощи которых можно отличить левую триаду картинок от правой. Решение данных задач требует моделирования логического мышления в полном объеме.
В целом проблема распознавания образов состоит из двух частей: обучения и распознавания. Обучение осуществляется путем показа отдельных объектов с указанием их принадлежности тому или другому образу. В результате обучения распознающая система должна приобрести способность реагировать одинаковыми реакциями на все объекты одного образа и различными - на все объекты различных образов. Очень важно, что процесс обучения должен завершиться только путем показов конечного числа объектов без каких-либо других подсказок. В качестве объектов обучения могут быть либо картинки, либо другие визуальные изображения (буквы), либо различные явления внешнего мира, например, звуки, состояния организма при медицинском диагнозе, состояние технического объекта в системах управления и др. Важно, что в процессе обучения указываются только сами объекты и их принадлежность образу. За обучением следует процесс распознавания новых объектов, который характеризует действия уже обученной системы. Автоматизация этих процедур и составляет проблему обучения распознаванию образов. В том случае, когда человек сам разгадывает или придумывает, а затем навязывает машине правило классификации, проблема распознавания решается частично, так как основную и главную часть проблемы (обучение) человек берет на себя.
Проблема обучения распознаванию образов интересна как с прикладной, так и с принципиальной точки зрения. С прикладной точки зрения решение этой проблемы важно прежде всего потому, что оно открывает возможность автоматизировать многие процессы, которые до сих пор связывали лишь с деятельностью живого мозга. Принципиальное значение проблемы тесно связано с вопросом, который все чаще возникает в связи с развитием идей кибернетики: что может и что принципиально не может делать машина? В какой мере возможности машины могут быть приближены к возможностям живого мозга? В частности, может ли машина развить в себе способность перенять у человека умение производить определенные действия в зависимости от ситуаций, возникающих в окружающей среде? Пока стало ясно только то, что если человек может сначала сам осознать свое умение, а потом его описать, т. е. указать, почему он производит действия в ответ на каждое состояние внешней среды или как (по какому правилу) он объединяет отдельные объекты в образы, то такое умение без принципиальных трудностей может быть передано машине. Если же человек обладает умением, но не может объяснить его, то остается только один путь передачи умения машине - обучение примерами.
Круг задач, которые могут решаться с помощью распознающих систем, чрезвычайно широк. Сюда относятся не только задачи распознавания зрительных и слуховых образов, но и задачи распознавания сложных процессов и явлений, возникающих, например, при выборе целесообразных действий руководителем предприятия или выборе оптимального управления технологическими, экономическими, транспортными или военными операциями. В каждой из таких задач анализируются некоторые явления, процессы, состояния внешнего мира, всюду далее называемые объектами наблюдения. Прежде чем начать анализ какого-либо объекта, нужно получить о нем определенную, каким-либо способом упорядоченную информацию. Такая информация представляет собой характеристику объектов, их отображение на множестве воспринимающих органов распознающей системы.
Но каждый объект наблюдения может воздействовать на нас по-разному, в зависимости от условий восприятия. Например, какая-либо буква, даже одинаково написанная, может в принципе как угодно смещаться относительно воспринимающих органов. Кроме того, объекты одного и того же образа могут достаточно сильно отличаться друг от друга и, естественно, по-разному воздействовать на воспринимающие органы.
Каждое отображение какого-либо объекта на воспринимающие органы распознающей системы, независимо от его положения относительно этих органов, принято называть изображением объекта, а множества таких изображений, объединенные какими-либо общими свойствами, представляют собой образы.
При решении задач управления методами распознавания образов вместо термина "изображение" применяют термин "состояние". Состояние - это определенной формы отображение измеряемых текущих (или мгновенных) характеристик наблюдаемого объекта. Совокупность состояний определяет ситуацию. Понятие "ситуация" является аналогом понятия "образ". Но эта аналогия не полная, так как не всякий образ можно назвать ситуацией, хотя всякую ситуацию можно назвать образом.
Ситуацией принято называть некоторую совокупность состояний сложного объекта, каждая из которых характеризуется одними и теми же или схожими характеристиками объекта. Например, если в качестве объекта наблюдения рассматривается некоторый объект управления, то ситуация объединяет такие состояния этого объекта, в которых следует применять одни и те же управляющие воздействия. Если объектом наблюдения является военная игра , то ситуация объединяет все состояния игры, которые требуют, например, мощного танкового удара при поддержке авиации.
Выбор исходного описания объектов является одной из центральных задач проблемы ОРО. При удачном выборе исходного описания (пространства признаков) задача распознавания может оказаться тривиальной, и наоборот, неудачно выбранное исходное описание может привести либо к очень сложной дальнейшей переработке информации, либо вообще к отсутствию решения. Например, если решается задача распознавания объектов, отличающихся по цвету, а в качестве исходного описания выбраны сигналы, получаемые от датчиков веса, то задача распознавания в принципе не может быть решена.
Под образом понимается структурированное описание изучаемого объекта или явления, представленное вектором признаков, каждый элемент которого представляет числовое значение одного из признаков, характеризующих соответствующий объект.
Общая структура системы распознавания имеет следующий вид:
Смысл задачи распознавания – установить, обладают ли изучаемые объекты фиксированным конечным набором признаков, позволяющих отнести их к определенному классу. Задачи распознавания имеют следующие характерные черты:
1. Это информационные задачи, состоящие из двух этапов:
a. Приведение исходных данных к виду, удобному для распознавания.
b. Собственно распознавание – указание принадлежности объекта определенному классу.
2. В этих задачах можно вводить понятие аналогии или подобия объектов и формулировать понятие близости объектов в качестве основания для зачисления объектов в один и тот же класс или разные классы.
3. В этих задачах можно оперировать набором прецедентов – примеров, классификация которых известна и которые в виде формализованных описаний могут быть предъявлены алгоритму распознавания для настройки на задачу в процессе обучения.
4. Для этих задач трудно строить формальные теории и применять классические математические методы: часто информация для точной математической модели или выигрыш от использования модели и математических методов несоизмерим с затратами.
5. В этих задачах возможна «плохая информация» - информация с пропусками, разнородная, косвенная, нечеткая, неоднозначная, вероятностная.
Целесообразно выделять следующие типы задач распознавания:
1. Задача распознавания, то есть отнесение предъявленного объекта по его описанию к одному из заданных классов (обучение с учителем).
2. Задача автоматической классификации – разбиение множества объектов (ситуаций) по их описаниям на систему непересекающихся классов (таксономия, кластерный анализ, обучение без учителя).
3. Задача выбора информативного набора признаков при распознавании.
4. Задача приведения исходных данных к виду, удобному для распознавания.
5. Динамическое распознавание и динамическая классификация – задачи 1 и 2 для динамических объектов.
6. Задача прогнозирования – задачи 5, в которых решение должно относиться к некоторому моменту в будущем.
Понятие образа.
Образ, класс – классификационная группировка в системе, объединяющая (выделяющая) определенную группу объектов по некоторому признаку. Образы обладают рядом характерных свойств, проявляющихся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей.
В качестве образа можно рассматривать и некоторую совокупность состояний объекта управления, причем вся эта совокупность состояний характеризуется тем, что для достижения заданной цели требуется одинаковое воздействие на объект. Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты.
В целом, проблема распознавания образов состоит из двух частей: обучение и распознавание.
Обучение осуществляется путем показа отдельных объектов с указанием их принадлежности тому или другому образу. В результате обучения распознающая система должна приобрести способность реагировать одинаковыми реакциями на все объекты одного образа и различными – на все объекты различных образов.
Очень важно, что процесс обучения должен завершиться только путем показов конечного числа объектов без каких-либо других подсказок. В качестве объектов обучения могут быть либо визуальные изображения, либо различные явления внешнего мира и другие.
За обучением следует процесс распознавания новых объектов, который характеризует действие уже обученной системы. Автоматизация этих процедур и составляет проблему обучения распознаванию образов. В том случае, когда человек сам разгадывает или придумывает, а затем навязывает ЭВМ правила классификации, проблема распознавания решается частично, так как основную и главную часть проблемы (обучение) человек берет на себя.
Проблема обучения распознаванию образов интересна как с прикладной, так и с принципиальной точки зрения. С прикладной точки зрения, решение этой проблемы важно прежде всего потому, что оно открывает возможность автоматизировать многие процессы, которые до сих пор связывали лишь с деятельностью живого мозга. Принципиальное значение проблемы связано с вопросом, что может и что принципиально не может делать ЭВМ.
При решении задач управления методами распознавания образов вместо термина «образ» применяется термин «состояние». Состояние – определенные формы отображения измеряемых текущих (мгновенных) характеристик наблюдаемого объекта, совокупность состояний определяет ситуацию.
Ситуацией принято называть некоторую совокупность состояний сложного объекта, каждое из которых характеризуется одними и теми же или схожими характеристиками объекта. Например, если в качестве объекта наблюдения рассматривается некоторый объект управления, то ситуация объединяет такие состояния этого объекта, в которых следует применять одни и те же управляющие воздействия. Если объектом наблюдения является игра, то ситуация объединяет все состояния игры.
Выбор исходного описания объектов является одной из центральных задач проблемы обучения распознаванию образов. При удачном выборе исходного описания (пространство признаков) задача распознавания может оказаться тривиальной. И наоборот, неудачно выбранное исходное описание может привести либо к очень сложной дальнейшей переработке информации, либо вообще к отсутствию решения.
Геометрический и структурный подходы.
Любое изображение, которое возникает в результате наблюдения какого-либо объекта в процессе обучения или экзамена, можно представить в виде вектора, а значит, и в виде точки некоторого пространства признаков.
Если утверждается, что при показе изображений возможно однозначно отнести их к одному из двух (или нескольких) образов, то тем самым утверждается, что в некотором пространстве существуют две или несколько областей, не имеющих общих точек, и что изображение точки из этих областей. Каждой точки такой области можно приписать наименование, то есть дать название, соответствующее образу.
Проинтерпретируем в терминах геометрической картины процесс обучения распознаванию образов, ограничившись пока случаем распознавания только двух образов. Заранее считается известным лишь то, что требуется разделить две области в некотором пространстве и что показываются точки только их этих областей. Сами эти области заранее не определены, то есть нет каких-либо сведений о расположении их границ или правил определения принадлежности точки к той или иной области.
В ходе обучения предъявляются точки, случайно выбранные из этих областей, и сообщается информация о том, к какой области принадлежат предъявляемые точки. Никакой дополнительной информации об этих областях, то есть о расположении их границ в ходе обучения не сообщается.
Цель обучения состоит либо в построении поверхности, которая разделяла бы не только показанные в процессе обучения точки, но и все остальные точки, принадлежащие этим областям, либо в построении поверхностей, ограничивающих эти области так, чтобы в каждой из них находились только точки одного образа. Иначе говоря, цель обучения состоит в построении таких функций от векторов-изображений, которые были бы, например, положительны на всех точках одного и отрицательны на всех точках другого образа.
В связи с тем, что области не имеют общих точек, всегда существует целое множество таких разделяющих функций, а в результате обучения должна быть построена одна из них. Если предъявляемые изображения принадлежат не двум, а большему числу образов, то задача состоит в построении по показанным в ходе обучения точкам поверхности, разделяющей все области, соответствующие этим образам, друг от друга.
Эта задача может быть решена, например, путем построения функции, принимающей над точками каждой из областей одинаковое значение, а над точками из разных областей значение этой функции должно быть различно.
Может показаться, что знания всего лишь некоторого количества точек из области недостаточно, чтобы отделить всю область. Действительно можно указать бесчисленное количество различных областей, которые содержат эти точки, и как бы ни была построена по ним поверхность, выделяющая область, всегда можно указать другую область, которая пересекает поверхность и вместе с тем содержит показанные точки.
Однако известно, что задача о приближении функции по информации о ней в ограниченном множестве точек является существенно более узкой, чем все множество, на котором функция задана, и является обычной математической задачей об аппроксимации функций. Разумеется, решение таких задач требует введения определенных ограничений на классе рассматриваемых функций, а выбор этих ограничений зависит от характера информации, которую может добавить учитель в процесс обучения.
Одной из таких подсказок является гипотеза о компактности образов.
Наряду с геометрической интерпретацией проблемы обучения распознаванию образов, существует и иной подход, который назван структурным, или лингвистическим. Рассмотрим лингвистический подход на примере распознавания зрительных изображений.
Сначала выделяется набор исходных понятий – типичных фрагментов, встречающихся на изображении, и характеристик взаимного расположения фрагментов (слева, снизу, внутри и т.д.). Эти исходные понятия образуют словарь, позволяющий строить различные логические высказывания, иногда называемые предложениями.
Задача состоит в том, чтобы из большого количества высказываний, которые могли бы быть построены с использованием этих понятий, отобрать наиболее существенные для данного конкретного случая. Далее, просматривая конечное и по возможности небольшое число объектов из каждого образа, нужно построить описание этих образов.
Построенные описания должны быть столь полными, чтобы решить вопрос о том, к какому образу принадлежит данный объект. При реализации лингвистического подхода возникают две задачи: задача построения исходного словаря, то есть набора типичных фрагментов, и задача построения правил описания из элементов заданного словаря.
В рамках лингвистической интерпретации проводится аналогия между структурой изображений и синтаксисом языка. Стремление к этой аналогии было вызвано возможностью использовать аппарат математической лингвистики, то есть методы по своей природе являются синтаксическими. Использование аппарата математической лингвистики для описания структуры изображений можно применять только после того, как произведена сегментация изображений на составные части, то есть выработаны слова для описания типичных фрагментов и методы их поиска.
После предварительной работы, обеспечивающей выделение слов, возникают собственно лингвистические задачи, состоящие из задач автоматического грамматического разбора описаний для распознавания изображений.
Гипотеза компактности.
Если предположить, что в процессе обучения пространство признаков формируется исходя из задуманной классификации, то тогда можно надеяться, что задание пространства признаков само по себе задает свойство, под действием которого образы в этом пространстве легко разделяются. Именно эти надежды по мере развития работ в области распознавания образов стимулировали появление гипотезы компактности, которая гласит: образам соответствуют компактные множества в пространстве признаков.
Под компактным множеством будем понимать некие сгустки точек в пространстве изображений, предполагая, что между этими сгустками существуют разделяющие их разряжения. Однако эту гипотезу не всегда удавалось подтвердить экспериментально. Но те задачи, в рамках которых гипотеза компактности хорошо выполнялась, всегда находили простое решение и наоборот, те задачи, для которых гипотеза не подтверждалась, либо совсем не решались, либо решались с большим трудом и привлечением дополнительной информации.
Сама гипотеза компактности превратилась в признак возможности удовлетворительно решения задач распознавания.
Формулировка гипотеза компактности подводит вплотную к понятию абстрактного образа. Если координаты пространства выбирать случайно, то и изображения в нем будут распределены случайно. Они будут в некоторых частях пространства располагаться более плотно, чем в других.
Назовем некоторое случайно выбранное пространство абстрактным изображением. В этом абстрактном пространстве почти наверняка будут существовать компактные множества точек. Поэтому, в соответствии с гипотезой компактности, множество объектов, которым в абстрактном пространстве соответствуют компактные множества точек, принято называть абстрактными образами заданного пространства.
Обучение и самообучение, адаптация и обучение.
Если бы удалось подметить некое всеобщее свойство, не зависящее ни от природы образов, ни от их изображений, а определяющее лишь способность к разделимости, то наряду с обычной задачей обучения распознаванию с использованием информации о принадлежности каждого объекта из обучающей последовательности тому или иному образу, можно было бы поставить иную классификационную задачу – так называемую задачу обучения без учителя.
Задачу такого рода на описательном уровне можно сформулировать следующим образом: системе одновременно или последовательно предъявляются объекты без каких-либо указаний об их принадлежности к образам. Входное устройство системы отображает множество объектов на множество изображений и, используя некоторое заложенное в нем заранее свойство разделимости образов, производит самостоятельную классификацию этих объектов.
После такого процесса самообучения система должна приобрести способность к распознаванию не только уже знакомых объектов (объектов из обучающей последовательности), но и тех, которые ранее не предъявлялись. Процессом самообучения некоторой системы называется такой процесс, в результате которого эта система без подсказки учителя приобретает способность к выработке одинаковых реакций на изображения объектов одного и того же образа и различных реакций на изображения различных образов.
Роль учителя при этом состоит лишь в подсказке системе некоторого объективного свойства, одинакового для всех образов и определяющего способность к разделению множества объектов на образы.
Оказывается, таким объективным свойством является свойство компактности образов. Взаимное расположение точек в выбранном пространстве уже содержит информацию о том, как следует разделить множество точек. Эта информация и определяет то свойство разделимости образов, которое оказывается достаточным для самообучения системы распознаванию образов.
Большинство известных алгоритмов самообучения способны выделять только абстрактные образы, то есть компактные множества в заданных пространствах. Различие между ними состоит в формализации понятия компактности. Однако это не снижает, а иногда и повышает ценность алгоритмов самообучения, так как часто сами образы заранее никем не определены, а задача состоит в том, чтобы определить, какие подмножества изображений в заданном пространстве представляют собой образы.
Примером такой постановки задачи являются социологические исследования, когда по набору вопросов выделяются группы людей. В таком понимании задачи алгоритмы самообучения генерируют заранее неизвестную информацию о существовании в заданном пространстве образов, о которых ранее никто не имел никакого представления.
Кроме того, результат самообучения характеризует пригодность выбранного пространства для конкретной задачи обучения распознаванию. Если абстрактные образы, выделяемые в пространстве самообучения, совпадают с реальными, то пространство выбрано удачно. Чем сильнее абстрактные образы отличаются от реальных, тем неудобнее выбранное пространство для конкретной задачи.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Механизм генерации этой корректировки практически полностью определяет алгоритм обучения.
Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация – процесс изменения параметров и структуры системы, а возможно, и управляющих воздействий, на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Обучение – процесс, в результате которого система постепенно приобретает способность отвечать нужными реакциями на определенные совокупности внешних воздействий, а адаптация – подстройка параметров и структуры системы с целью достижения требуемого качества управления в условиях непрерывных изменений внешних условий.
Системы распознавания речи.
Речь выступает в роли основного средства коммуникации между людьми и поэтому речевое общение считается одним из важнейших компонентов системы искусственного интеллекта. Распознавание речи представляет собой процесс преобразования акустического сигнала, формируемого на выходе микрофона или телефона, в последовательность слов.
Более сложной задачей является задача понимания речи, которая сопряжена с выявлением смысла акустического сигнала. В этом случае выход подсистемы распознавания речи служит входом подсистемы понимания высказываний. Автоматическое распознавание речи (системы АРР) является одним из направлений технологий обработки естественного языка.
Автоматическое распознавание речи применяется при автоматизации ввода текстов в ЭВМ, при формировании устных запросов к базам данных или информационно-поисковым системам при формировании устных команд различным интеллектуальным устройствам.
Основные понятия систем распознавания речи.
Системы распознавания речи характеризуются многими параметрами.
Одним из основных параметров является ошибка распознавания слов (ОРС). Этот параметр представляет собой отношение количества нераспознанных слов к общему количеству произнесенных слов.
Другими параметрами, характеризующими системы автоматического распознавания речи, являются:
1) размер словаря,
2) режим речи,
3) стиль речи,
4) предметная область,
5) дикторозависимость,
6) уровень акустических шумов,
7) качество входного канала.
В зависимости от размера словаря системы АРР подразделяются на три группы:
С малым размером словаря (до 100 слов),
Со средним размером словаря (от 100 слов до нескольких тысяч слов),
С большим размером словаря (более 10 000 слов).
Режим речи характеризует способ произнесения слов и фраз. Выделяют системы распознавания слитной речи и системы, позволяющие распознавать только изолированные слова речи. В режиме распознавания изолированных слов требуется, чтобы диктор делал краткие паузы между словами.
По стилю речи системы АРР подразделяются на две группы: системы детерминированной речи и системы спонтанной речи.
В системах распознавания детерминированной речи диктор воспроизводит речь, следуя грамматическим правилам языка. Спонтанная речь характеризуется нарушениями грамматических правил и ее сложнее распознавать.
В зависимости от предметной области выделяют системы АРР, ориентированные на применение в узкоспециальных областях (например, доступ к базам данных) и системы АРР с неограниченной областью применения. Последние требуют наличия большого объема словаря и должны обеспечивать распознавание спонтанной речи.
Многие системы автоматического распознавания речи являются дикторозависимыми. Это предполагает предварительную настройку системы на особенности произношения конкретного диктора.
Сложность решения задачи распознавания речи объясняется большой изменчивостью акустических сигналов. Эта изменчивость объясняется несколькими причинами:
Во-первых, различной реализацией фонем – основных единиц звукового строя языка. Изменчивость реализации фонем вызвана влиянием соседних звуков в потоке речи. Оттенки реализации фонем, обусловленные звуковым окружением, называют аллофонами.
Во-вторых, положением и характеристиками акустических приемников.
В-третьих, изменениями параметрами речи одного и того же диктора, которые обусловлены различным эмоциональным состоянием диктора, темпом его речи.
На рисунке представлены основные компоненты системы распознавания речи:
Оцифрованный речевой сигнал поступает на блок предварительной обработки, где осуществляется выделение признаков, необходимых для распознавания звуков. Распознавание звуков часто осуществляется с помощью моделей искусственных нейронных сетей. Выделенные звуковые единицы используют в дальнейшем для поиска последовательности слов, в наибольшей степени соответствующей входному речевому сигналу.
Поиск последовательности слов выполняется с помощью акустической, лексической и языковой моделей. Параметры моделей определяют по обучающим данным на основе соответствующих алгоритмов обучения.
Синтез речи по тексту. Основные понятия
Во многих случаях создание систем искусственного интеллекта с элементами ея-общения требуют вывода сообщений в речевой форме. На рисунке представлена структурная схема интеллектуальной вопросно-ответной системы с речевым интерфейсом:
Рисунок 1.
Кусок лекций взять у Олега
Рассмотрим особенности эмпирического подхода на примере распознавания частей речи. Задача состоит в присвоении словам предложения меток: существительное, глагол, предлог, прилагательное и тому подобное. Кроме этого, необходимо определять некоторые дополнительные признаки существительных и глаголов. Например, для существительного – число, а для глагола – форму. Формализуем задачу.
Представим предложение в виде последовательности слов: W=w1 w2…wn, где wn – случайные переменные, каждая из которых получает одно из возможных значений, принадлежащих словарю языка. Последовательность меток, назначаемых словам предложения, представим последовательностью X=x1 x2 … xn, где xn – случайные переменные, значения которых определены на множестве возможных меток.
Тогда задача распознавания частей речи состоит в поиске наиболее вероятной последовательности меток x1, x2, …, xn по заданной последовательности слов w1, w2, …, wn. Иными словами, необходимо найти такую последовательность меток X*=x1 x2 … xn, которая обеспечивает максимум условной вероятности P(x1, x2, …, xn| w1 w2.. wn).
Перепишем условную вероятность P(X| W) в следующем виде P(X| W)=P(X,W) / P(W). Так как требуется найти максимум условной вероятности P(X,W) по переменной X, получим X*=arg x max P(X,W). Совместную вероятность P(X,W) можно записать в виде произведения условных вероятностей: P(X,W)=произведение по и-1 до н от P(x i |x1,…,x i -1 , w1,…,w i -1) P(w i |x1,…,x i -1 , w1,…,w i -1). Непосредственный поиск максимума данного выражения представляет собой сложную задачу, так как при больших значениях n поисковое пространство становится очень большим. Поэтому вероятности, которые записаны в этом произведении, аппроксимируют более простыми условными вероятностями: P(x i |x i -1) P(w i |w i -1). В этом случае полагают, что значение метки x i связано только с предыдущей меткой x i -1 и не зависит от более ранних меток, а также что вероятность слова w i определяется только текущей меткой x i . Указанные предположения называют марковскими, а для решения задачи привлекают теорию марковских моделей. С учетом марковских предположений можно записать:
X*= arg x1, …, xn max П i =1 n P(x i |x i -1) P(wi|wi-1)
Где условные вероятности оцениваются на множестве обучающих данных
Поиск последовательности меток Х* осуществляют с помощью алгоритма динамического программирования Витерби. Алгоритм Витерби может рассматриваться как вариант алгоритма поиска на графе состояний, где вершинам соответствуют метки слов.
Характерно, что для любой текущей вершины множество дочерних меток всегда одно и то же. Более того, для каждой дочерней вершины множества родительских вершин тоже совпадают. Это объясняется тем, что на графе состояний осуществляются переходы с учетом всех возможных сочетаний меток. Предположение Маркова обеспечивают существенное упрощение задачи распознавания частей речи при сохранении высокой точности назначения меток словам.
Так, при наличии 200 меток точность назначения примерно равна 97%. Долгое время имперический анализ выполнялся с помощью стохастических контекстно-свободных грамматик. Однако для них характерен существенный недостаток. Он заключается в том, что различным грамматическим разборам могут назначаться одинаковые вероятности. Это происходит из-за того, что вероятность грамматического разбора представляется в виде произведения вероятностей правил, участвующих в разборе. Если в ходе разбора используются различные правила, характеризуемые одинаковыми вероятностями, то это и порождает указанную проблему. Лучшие результаты дает грамматика, учитывающая лексику языка.
В этом случае в правила включаются необходимые лексические сведения, которые обеспечивают различные значения вероятности для одного и того же правила в разных лексических окружениях. Имперический синтаксический анализ в большей степени соответствует распознаванию образов, чем традиционному грамматическому разбору в его классическом понимании.
Сравнительные исследования показали, что правильность имперического грамматического разбора приложений естественного языка оказывается выше по сравнению с традиционным грамматическим разбором.